Chapter 1: Introduction to Synthetic Data
1.1 What Is Synthetic Data?
Synthetic data is artificially generated information that mimics the statistical properties and structural patterns of real-world data, without being derived directly from actual observations. The concept was formalized in the statistical disclosure limitation literature by Rubin [1], who proposed generating entirely synthetic datasets from posterior predictive distributions fitted to confidential survey data. Rubin's key insight was that if a model adequately captures the joint distribution of the original variables, samples drawn from that model can serve as useful substitutes for some analyses while reducing direct exposure of individual records. Formal privacy still requires separate controls and auditing.
To understand synthetic data properly, it must be distinguished from related but distinct concepts. Real data consists of actual observations collected from the world — customer transactions, sensor readings, medical records, survey responses. Anonymized data attempts to obscure individual identity through techniques such as suppression, generalization, or hashing; however, Sweeney [2] demonstrated that even simple linkage attacks can re-identify individuals from ostensibly anonymized records — famously showing that 87% of the U.S. population could be uniquely identified by ZIP code, date of birth, and sex alone. Narayanan and Shmatikov [3] further showed that anonymized Netflix viewing histories could be de-anonymized by cross-referencing with public IMDb profiles.
Augmented data is a hybrid approach where synthetic instances are generated based on existing real data and then mixed into the original dataset to increase volume or improve model generalization. Techniques such as SMOTE [4] fall into this category — they interpolate between real minority-class examples rather than sampling from a learned distribution.
Synthetic data stands apart because it is entirely generated — often without reference to specific individuals. If you generate a dataset of 100,000 customer records using a statistical model trained on aggregate patterns, none of those records correspond to an actual person, yet the aggregate age distribution, income patterns, and purchase behaviors can closely match real populations. The formal distinction was sharpened by Reiter [5], who introduced the framework of partially synthetic and fully synthetic data, along with valid inference procedures for each.
1.2 A Brief History of Synthetic Data
The intellectual roots of synthetic data generation extend deeper than most practitioners realize. The practice emerged from classical statistical and computational traditions long before the era of deep learning.
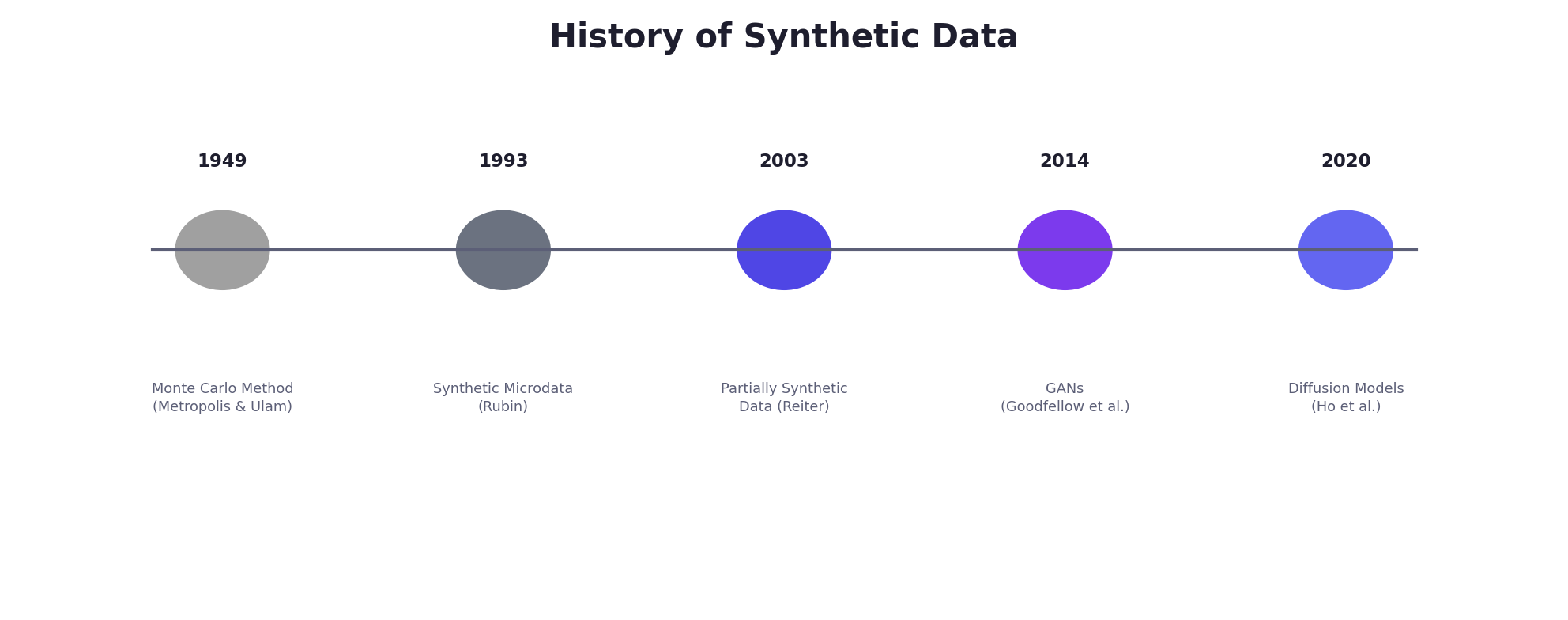
The Monte Carlo Revolution (1940s–1960s)
The formal birth of computational synthetic data traces to the Monte Carlo method, developed during the Manhattan Project by Stanislaw Ulam and John von Neumann [6]. Facing intractable integral equations governing neutron diffusion, Ulam realized that random sampling from probability distributions could approximate solutions to problems that resisted analytical treatment. The method's name — inspired by the casinos of Monaco — reflected the deliberate use of randomness to solve deterministic problems.
Metropolis and Ulam [7] published the foundational paper describing the statistical approach to neutron chain reactions in 1949. Shortly after, Metropolis et al. [8] introduced the Metropolis algorithm for sampling from complex probability distributions, establishing the Markov Chain Monte Carlo (MCMC) framework that remains central to Bayesian statistics and generative modeling today.
Statistical Disclosure Control (1990s–2000s)
The direct lineage of modern synthetic data begins with statistical agencies concerned about releasing microdata — individual-level records from censuses and surveys — without compromising respondent confidentiality. Rubin [1] proposed the idea of replacing real survey responses with draws from the posterior predictive distribution of a Bayesian model. Little [9] refined these ideas, and Reiter [5] developed the theory of partially synthetic datasets in which only sensitive variables are replaced with synthetic values while non-sensitive variables retain their real values. Reiter also provided the inferential framework — showing how multiple synthetic datasets could yield valid point estimates and confidence intervals through combining rules analogous to Rubin's multiple imputation formulas [10].
The U.S. Census Bureau became an early adopter, producing the Longitudinal Business Database (LBD) synthetic data product [11] and later exploring synthetic versions of the American Community Survey. These efforts demonstrated that national statistical agencies could release useful data products while providing formal privacy protections.
The Deep Generative Revolution (2014–Present)
The modern synthetic data boom is inseparable from advances in deep generative models. Generative Adversarial Networks (GANs), introduced by Goodfellow et al. [12] in 2014, demonstrated that neural networks could generate remarkably realistic synthetic samples by training a generator and discriminator in an adversarial game. Kingma and Welling [13] introduced the Variational Autoencoder (VAE) framework, providing an alternative generative approach grounded in variational inference.
For tabular data specifically, Xu et al. [14] introduced CTGAN (Conditional Tabular GAN), which addressed the unique challenges of mixed-type tabular data — continuous and categorical columns, multi-modal distributions, and class imbalance — through mode-specific normalization and training-by-sampling. This work catalyzed an ecosystem of tabular synthesis tools, including the Synthetic Data Vault (SDV) framework [15].
Concurrently, diffusion models [16][17] emerged as a powerful alternative, demonstrating superior sample quality and training stability compared to GANs for image generation. Ho et al. [17] showed that denoising diffusion probabilistic models (DDPMs) could match or exceed GAN quality while avoiding mode collapse, and subsequent work extended these models to text, audio, video, and structured data.
Privacy concerns further accelerated adoption. The European Union's General Data Protection Regulation (GDPR), adopted in 2016 and applicable from 2018, imposed strict constraints on personal data processing. Dwork et al. [18] had already laid the mathematical foundations of differential privacy — a framework that would prove essential for providing formal privacy guarantees in synthetic data generation. The convergence of powerful generative models and regulatory pressure created the conditions for synthetic data to become a multi-billion-dollar industry.
1.3 Why Synthetic Data Matters Now
The explosion of interest in synthetic data is driven by several converging pressures that make it increasingly indispensable for modern data science and machine learning.
Data Scarcity and Class Imbalance
Real-world datasets are often limited, particularly for rare phenomena. In medical imaging, a hospital may have annotated scans for only a few hundred cases of a rare disease. In autonomous driving, critical edge cases — pedestrians in heavy snow, cyclists at night — occur infrequently in real recordings. Shorten and Khoshgoftaar [19] provide a comprehensive survey of data augmentation techniques for deep learning, documenting how synthetic data augmentation can substantially improve model generalization when real data is scarce. Chawla et al. [4] showed that even simple synthetic oversampling (SMOTE) can significantly improve classifier performance on imbalanced datasets.
Privacy Regulations and Data Sharing
GDPR, HIPAA, PIPEDA, and dozens of other regulations constrain how organizations can use and share personal data. El Emam et al. [20] demonstrated that synthetic data can preserve analytical utility while reducing re-identification risk below acceptable thresholds, enabling data sharing across organizational boundaries. A pharmaceutical company can share synthetic patient cohorts for multi-site research collaboration without exposing real health records — provided the synthetic data generation process includes appropriate privacy safeguards.
Cost of Annotation and Labeling
High-quality labeled data is expensive. Annotating medical images requires radiologist time at hundreds of dollars per hour. Labeling customer complaints demands domain expertise. Ratner et al. [21] introduced the concept of data programming through the Snorkel framework, showing that programmatic labeling functions — including synthetic label generation — could reduce the labeling bottleneck by orders of magnitude while maintaining acceptable accuracy for downstream models.
Bias and Fairness
Real datasets carry historical biases. Loan approval data reflects past discrimination; face recognition datasets are skewed toward certain demographics [22]. Synthetic data offers a mechanism for counterfactual reasoning: Xu et al. [23] explored fairness-aware synthetic data generation, demonstrating that careful conditioning during generation can produce datasets that maintain utility while achieving better demographic balance than the original data.
Testing, Development, and Reproducibility
Developers building ML systems need realistic test data, but using production data is risky and access-restricted. Synthetic data enables rapid iteration, stress-testing, and reproducible experimentation. The rise of ML benchmarking culture — driven by datasets like ImageNet [24] — has simultaneously highlighted the risks of benchmark overfitting and the potential for synthetic benchmarks that can be regenerated with controlled properties.
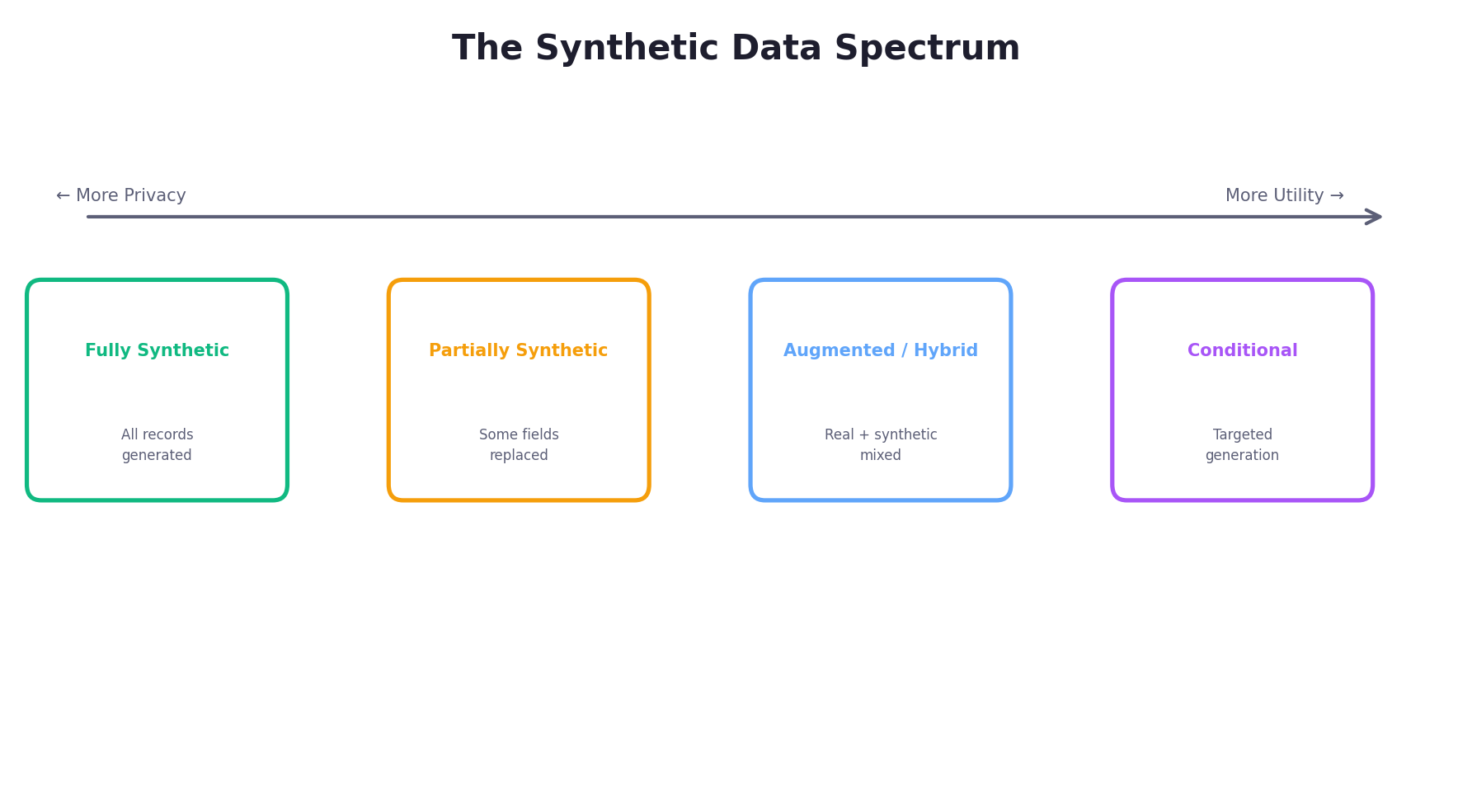
1.4 The Synthetic Data Spectrum
Synthetic data is not monolithic. Different strategies for generation sit along a spectrum, each trading off privacy, utility, and computational cost differently. The taxonomy was first formalized by Reiter [5] and later extended by Drechsler and Reiter [26].
Fully Synthetic Data
Every record is generated from scratch. A model is trained to capture the joint distribution of the original data, then samples entirely new instances. None of the synthetic records correspond to real individuals. Rubin [1] originally proposed this approach, and Raghunathan et al. [27] provided the first practical implementation using sequential regression imputation. Fully synthetic data offers the strongest privacy protection since no real individual's data appears in the release, but achieving high utility requires an accurate generative model.
Partially Synthetic Data
Some variables or some records are replaced with synthetic values while others remain real. Reiter [5] showed that this approach can offer strong privacy for the replaced variables while maintaining exact fidelity for the non-sensitive ones. The U.S. Census Bureau's Survey of Income and Program Participation (SIPP) Synthetic Beta used this approach, replacing only the most sensitive economic variables [11].
Augmented (Hybrid) Data
Real and synthetic data are mixed. A dataset of 5,000 real customers is augmented with 45,000 synthetic customers to increase training volume. This approach sacrifices some privacy (real data is still present) but can maximize utility, as the real records anchor the synthetic data to genuine distributions. This is common in computer vision, where geometric and photometric augmentations [19] have become standard practice.
Conditional Synthetic Data
Synthetic data is generated conditioned on specific attributes or scenarios — for example, generating synthetic patient records specifically for underrepresented demographic groups, or generating edge-case driving scenarios for autonomous vehicle testing. Conditional generation is essential for fairness-aware applications and targeted data augmentation, and has been formalized within the GAN framework through conditional GANs [28] and the conditional sampling mechanism in CTGAN [14].
1.5 A Simple First Example
Let us move from theory to practice. The following minimal Python example generates synthetic tabular data resembling customer records by sampling from parametric distributions with explicit correlation structure — the simplest incarnation of Rubin's [1] idea of drawing from a fitted model.
import numpy as np
import pandas as pd
# Set random seed for reproducibility
np.random.seed(42)
n_customers = 1000
# Generate correlated continuous features using a multivariate normal
# Specify means and a covariance matrix to encode correlations
means = [45, 65000, 1200] # age, income, purchase_amount
cov_matrix = [
[225, 45000, 3000], # age variance=225 (sd=15)
[45000, 4e8, 5e5], # income variance=4e8 (sd~20k)
[3000, 5e5, 2.5e5] # purchase variance=2.5e5 (sd~500)
]
samples = np.random.multivariate_normal(means, cov_matrix, size=n_customers)
ages = np.clip(samples[:, 0], 18, 80).astype(int)
incomes = np.clip(samples[:, 1], 20000, 250000).astype(int)
purchases = np.clip(samples[:, 2], 10, 5000).round(2)
# Categorical features with domain-driven probabilities
segments = np.random.choice(
['Premium', 'Standard', 'Budget'],
size=n_customers,
p=[0.2, 0.5, 0.3]
)
regions = np.random.choice(
['North', 'South', 'East', 'West'],
size=n_customers
)
synthetic_df = pd.DataFrame({
'age': ages,
'income': incomes,
'purchase_amount': purchases,
'segment': segments,
'region': regions
})
print(synthetic_df.head(10))
print(f"\nPearson correlation (age, income): "
f"{synthetic_df['age'].corr(synthetic_df['income']):.3f}")
print(f"Pearson correlation (income, purchase): "
f"{synthetic_df['income'].corr(synthetic_df['purchase_amount']):.3f}")This snippet generates 1,000 synthetic customer records using a multivariate normal distribution with an explicit covariance matrix. The key improvement over independent sampling is that correlations between variables — age and income, income and purchase amount — are preserved by design. This is a rudimentary version of the Gaussian copula approach that underlies many production synthetic data tools [15]. We will formalize these statistical foundations in Chapter 2.
np.random.seed(42) so that the same code always produces the same synthetic data. Reproducibility is essential for scientific validity — synthetic data experiments should be fully replicable [29].
1.6 Key Terminology
Synthetic data generation involves several recurring concepts. Understanding these terms — and their formal definitions — is essential for reading the research literature, evaluating tools, and designing generation systems.
- Fidelity
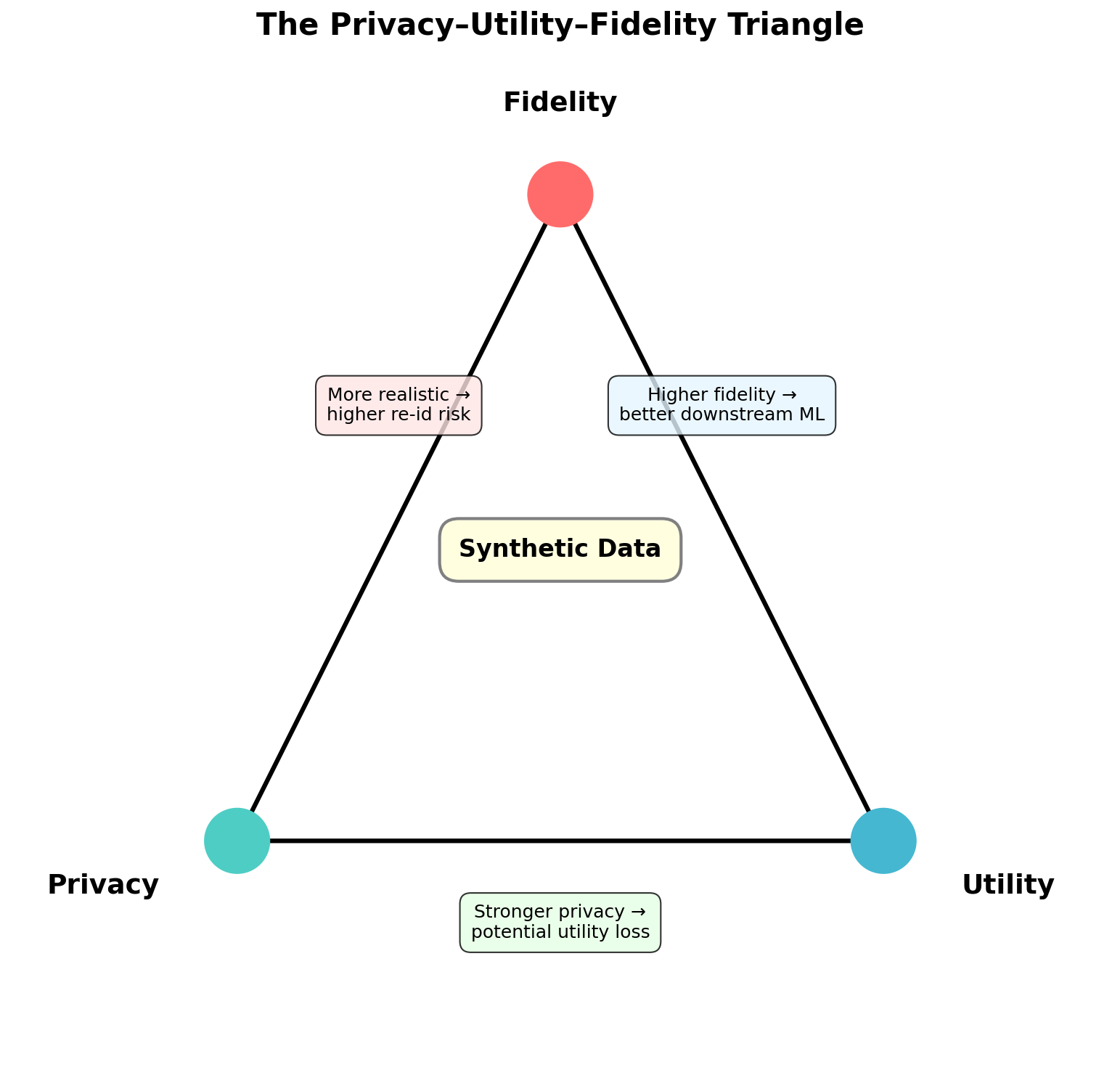
- The degree to which synthetic data resembles real data in its statistical properties. Fidelity is typically decomposed into marginal fidelity (do individual column distributions match?) and joint fidelity (are multivariate correlations preserved?). Common metrics include the Kolmogorov-Smirnov statistic, Jensen-Shannon divergence, and maximum mean discrepancy [30]. See Chapter 9 for a full treatment.
- Utility
- Whether synthetic data is useful for its intended purpose. The standard evaluation paradigm is Train on Synthetic, Test on Real (TSTR): train a model on synthetic data, evaluate on held-out real data, and compare performance to a model trained on real data [25]. High fidelity does not guarantee high utility — a dataset may match marginals perfectly but fail to preserve the decision boundary needed for a specific classification task.
- Privacy
- The degree to which synthetic data protects individuals from re-identification or inference attacks. Privacy can be measured empirically (e.g., distance to closest record, membership inference attack success rate) or guaranteed formally through differential privacy [18]. The crucial insight from the privacy literature is that synthetic data is not inherently private — a generative model can memorize and reproduce training examples [31].
- Disclosure Risk
- The probability that a specific individual's information can be inferred from a released dataset. Even fully synthetic data carries disclosure risk if rare subgroups in the training data are reproduced with high fidelity. Drechsler and Reiter [26] formalize disclosure risk measures for synthetic data and provide methods for empirical assessment.
- Differential Privacy (DP)
- A mathematical framework providing formal privacy guarantees. A randomized mechanism M satisfies ε-differential privacy if for all neighboring datasets D and D' (differing in one record) and all sets of outputs S: Pr[M(D) ∈ S] ≤ eε · Pr[M(D') ∈ S]. Smaller ε means stronger privacy. Dwork et al. [18] introduced the definition; Abadi et al. [32] showed how to train deep learning models with DP guarantees via DP-SGD. See Chapter 8 for details.
- Mode Collapse
- A failure mode in generative models — particularly GANs — where the generator learns to produce only a narrow subset of plausible outputs, ignoring other modes of the data distribution. Goodfellow [33] discusses this as one of the key open problems in GAN training. Mode collapse reduces both fidelity and utility.
- Membership Inference Attack
- An adversarial attack that attempts to determine whether a specific record was in the training set used to build a generative model. Shokri et al. [34] introduced shadow-model-based membership inference, and subsequent work has applied these techniques to evaluate the privacy of synthetic data releases. A well-generated synthetic dataset should resist such attacks.
1.7 When NOT to Use Synthetic Data
Synthetic data is powerful but not a panacea. There are well-documented scenarios where synthetic data generation is inappropriate, risky, or counterproductive.
High-stakes regulatory decisions. In clinical trials, regulatory agencies (FDA, EMA) require real-world evidence. While synthetic data can support trial design, power analysis, and exploratory modeling [35], it cannot substitute for real patient outcomes in pivotal studies. Similarly, financial audits require authentic transaction records.
Unknown or poorly characterized distributions. If the underlying real-world distribution is not well understood, synthetic data generation risks producing artifacts that do not correspond to reality. This is particularly dangerous for tail events and rare phenomena — precisely the cases where synthetic data is most tempting to use. Stadler et al. [36] demonstrated that generative models frequently fail to capture tail behavior, leading to overconfident risk assessments.
Privacy without validation. Generating fully synthetic data does not automatically guarantee privacy. Stadler et al. [36] showed that state-of-the-art synthetic data generators can leak substantial private information about training records, particularly for outliers. Synthetic data must be subjected to privacy auditing — membership inference attacks, distance-to-closest-record analysis — before release, not assumed safe.
Absence of ground truth for validation. If you cannot validate synthetic data against real observations (because the real data is unavailable or the domain is poorly understood), you have no way to assess whether your generative model is accurate. Using synthetic data in such settings risks compounding model error.
Regulatory prohibition. Some jurisdictions or industries explicitly restrict synthetic data for specific purposes. Fair-lending regulations may prohibit banks from using synthetic data to train credit approval models if the synthetic generation process cannot be shown to preserve fairness properties. Always consult domain-specific regulatory guidance.
1.8 What's Ahead
This chapter has laid the conceptual and historical foundations. The remaining chapters progressively deepen both theory and practice:
Chapter 2: Statistical Foundations formalizes the mathematical underpinnings — probability distributions, sampling, copulas, kernel density estimation, and maximum likelihood — that underlie all synthetic data generation methods.
Chapter 3: Rule-Based & Simulation Methods explores classical approaches: Monte Carlo simulation [7], agent-based modeling, and domain-specific generators like Faker and Synthea.
Chapter 4: Deep Learning for Synthetic Data introduces GANs [12], VAEs [13], normalizing flows, and diffusion models [17] — the architectures driving the current state of the art.
Chapter 5: LLMs & Synthetic Text covers the use of large language models for generating labeled NLP datasets, instruction-tuning data, and structured records.
Chapter 6: Synthetic Tabular Data focuses on the dominant enterprise use case, covering CTGAN [14], TVAE, Bayesian networks, and multi-table synthesis.
Chapter 7: Images, Video & Audio addresses synthetic multimedia — from StyleGAN to diffusion-based image synthesis, domain randomization for robotics, and synthetic speech.
Chapter 8: Privacy & Fairness provides a deep treatment of differential privacy [18], DP-SGD [32], membership inference attacks [34], and fairness-aware generation.
Chapter 9: Evaluation & Quality Metrics develops the measurement framework: statistical fidelity, TSTR utility, privacy metrics, and automated evaluation tools.
Chapters 10–12 ground the material in industry use cases, survey production tools and frameworks, and look ahead to emerging research directions.
Chapter 13: Time Series & Sequential Data extends the book into temporal generation, covering sequence-aware modeling choices, recurrent and diffusion-based generators, and the evaluation tricks needed when order matters as much as the values themselves.
Chapter 14: Synthetic Data Ops focuses on the operational layer: dataset lineage, release gates, privacy-budget tracking, monitoring, incident response, and the engineering discipline required to move synthetic data from a demo artifact to a dependable production asset.
Conclusion
Synthetic data is not a silver bullet, but it represents a fundamental shift in how we approach data-centric problems. It bridges the gap between the data we have and the data we need, enables privacy-preserving data sharing, and accelerates model development. Yet it demands careful thought: synthetic data can mislead if generated naively, leak private information if not audited, and amplify biases if not designed with fairness in mind.
The chapters ahead will equip you to navigate these tradeoffs with both theoretical rigor and practical skill. Let's begin.
References
- (1993). Discussion: Statistical disclosure limitation. Journal of Official Statistics, 9(2), 461–468.
- (2000). Simple demographics often identify people uniquely. Carnegie Mellon University, Data Privacy Working Paper 3.
- (2008). Robust de-anonymization of large sparse datasets. Proceedings of the 2008 IEEE Symposium on Security and Privacy, 111–125. doi:10.1109/SP.2008.33
- (2002). SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research, 16, 321–357. doi:10.1613/jair.953
- (2003). Inference for partially synthetic, public use microdata sets. Survey Methodology, 29(2), 181–188.
- (1987). Stan Ulam, John von Neumann, and the Monte Carlo method. Los Alamos Science, 15, 131–137.
- (1949). The Monte Carlo method. Journal of the American Statistical Association, 44(247), 335–341. doi:10.1080/01621459.1949.10483310
- (1953). Equation of state calculations by fast computing machines. The Journal of Chemical Physics, 21(6), 1087–1092. doi:10.1063/1.1699114
- (1993). Statistical analysis of masked data. Journal of Official Statistics, 9(2), 407–426.
- (1987). Multiple Imputation for Nonresponse in Surveys. New York: John Wiley & Sons.
- (2011). Towards unrestricted public use business microdata: The Synthetic Longitudinal Business Database. International Statistical Review, 79(3), 362–384. doi:10.1111/j.1751-5823.2011.00153.x
- (2014). Generative adversarial nets. Advances in Neural Information Processing Systems (NeurIPS), 27, 2672–2680.
- (2014). Auto-encoding variational Bayes. Proceedings of the 2nd International Conference on Learning Representations (ICLR). arXiv:1312.6114
- (2019). Modeling tabular data using conditional GAN. Advances in Neural Information Processing Systems (NeurIPS), 32.
- (2016). The Synthetic Data Vault. Proceedings of the IEEE International Conference on Data Science and Advanced Analytics (DSAA), 399–410. doi:10.1109/DSAA.2016.49
- (2015). Deep unsupervised learning using nonequilibrium thermodynamics. Proceedings of the 32nd International Conference on Machine Learning (ICML), 2256–2265.
- (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems (NeurIPS), 33, 6840–6851. arXiv:2006.11239
- (2006). Calibrating noise to sensitivity in private data analysis. Proceedings of the 3rd Theory of Cryptography Conference (TCC), 265–284. doi:10.1007/11681878_14
- (2019). A survey on image data augmentation for deep learning. Journal of Big Data, 6(1), 60. doi:10.1186/s40537-019-0197-0
- (2020). Practical Synthetic Data Generation: Balancing Privacy and the Broad Availability of Data. Sebastopol, CA: O'Reilly Media.
- (2017). Snorkel: Rapid training data creation with weak supervision. Proceedings of the VLDB Endowment, 11(3), 269–282. doi:10.14778/3157794.3157797
- (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. Proceedings of the Conference on Fairness, Accountability, and Transparency (FAccT), 77–91.
- (2018). Fairness-aware model-agnostic positive action approach for algorithmic fairness. Proceedings of the SIAM International Conference on Data Mining (SDM), 540–548.
- (2009). ImageNet: A large-scale hierarchical image database. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 248–255. doi:10.1109/CVPR.2009.5206848
- (2022). Synthetic data — what, why and how? arXiv preprint arXiv:2205.03257.
- (2011). An empirical evaluation of easily implemented, nonparametric methods for generating synthetic datasets. Computational Statistics & Data Analysis, 55(12), 3232–3243. doi:10.1016/j.csda.2011.06.006
- (2003). Multiple imputation for statistical disclosure limitation. Journal of Official Statistics, 19(1), 1–16.
- (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.
- (2021). Improving reproducibility in machine learning research. Journal of Machine Learning Research, 22(164), 1–20.
- (2012). A kernel two-sample test. Journal of Machine Learning Research, 13, 723–773.
- (2019). The secret sharer: Evaluating and testing unintended memorization in neural networks. Proceedings of the 28th USENIX Security Symposium, 267–284.
- (2016). Deep learning with differential privacy. Proceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS), 308–318. doi:10.1145/2976749.2978318
- (2016). NIPS 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160.
- (2017). Membership inference attacks against machine learning models. Proceedings of the IEEE Symposium on Security and Privacy, 3–18. doi:10.1109/SP.2017.41
- (2023). Assessing the credibility of computational modeling and simulation in medical device submissions: Guidance for industry and Food and Drug Administration staff. U.S. Food and Drug Administration.
- (2022). Synthetic data — anonymisation groundhog day. Proceedings of the 31st USENIX Security Symposium, 1451–1468.