Chapter 10: Industry Use Cases
10.1 Synthetic Data in Production: From Research to Real-World Deployment
Synthetic data has graduated from a theoretical novelty to a critical tool in production systems across industries. Enterprises now deploy synthetic data generators to augment training datasets, simulate edge cases, accelerate development timelines, and navigate complex regulatory landscapes. However, the journey from concept to production deployment reveals persistent challenges: bridging the fidelity-privacy gap, validating quality against ground truth, integrating with existing ML pipelines, and securing stakeholder trust.
The key difference between research synthetic data and production synthetic data lies in maturity and accountability. Research projects often tolerate high failure rates, accept degraded performance in exchange for privacy, or work with small-scale pilots. Production systems must deliver consistent quality, satisfy regulatory audits, maintain reproducibility, version control pipelines, and support rollback when quality degrades. Furthermore, production deployments must account for distribution shift: models trained on old synthetic data may fail when deployed against new real-world distributions.
This chapter explores how synthetic data is deployed across eight major industries, examining the specific technical and business challenges each faces, the generation methods that work in practice, validation strategies, and hard-won lessons.
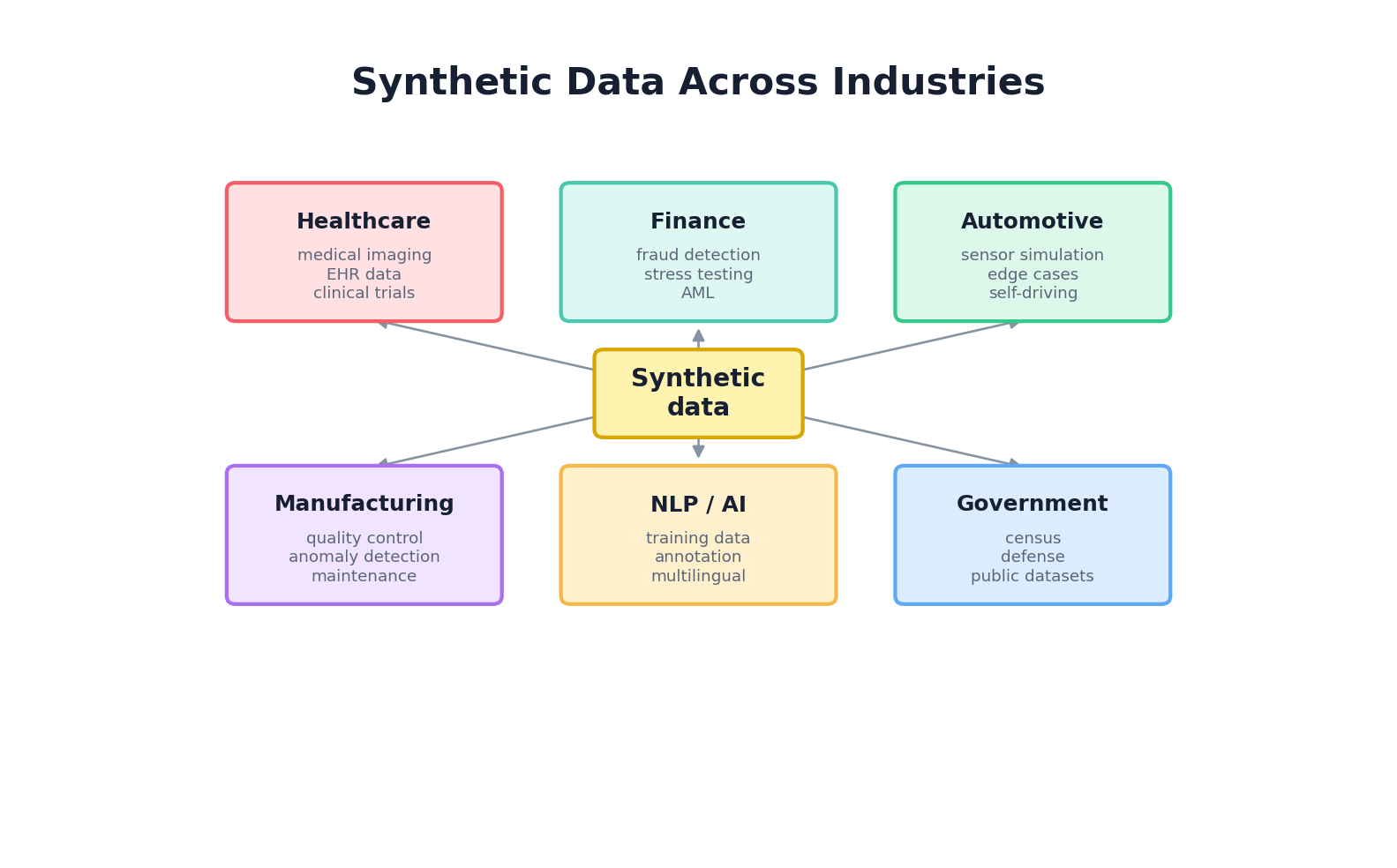
10.2 Healthcare & Life Sciences
Healthcare stands as the poster child for synthetic data adoption. Patient records contain some of the most sensitive personal information in existence: diagnoses, medications, genomic data, and mental health records. Yet healthcare organizations desperately need large, shareable datasets to train diagnostic AI, conduct population health studies, and develop new treatments. Synthetic patient data offers a pathway forward.
Synthea: Synthetic Patient Generator
Synthea is an open-source synthetic patient data generator developed by the MITRE Corporation. It uses rule-based simulation combined with statistical models to create realistic patient histories including demographics, conditions, medications, procedures, and lab results. Synthea has become the de facto standard for synthetic healthcare data in academic and commercial settings.
How Synthea works: Synthea simulates entire patient lifecycles. For each synthetic patient, it initializes demographic attributes (age, gender, race, socioeconomic status), then runs a disease simulation engine. The engine probabilistically assigns conditions based on demographic risk factors and disease prevalence in a target population. Once a condition is assigned, Synthea generates associated medications, lab tests, and procedures over time. The result is a realistic temporal sequence of healthcare events spanning decades.
Example—Diabetes patient generation: If a 55-year-old female patient is assigned Type 2 Diabetes (based on age and obesity prevalence in her demographic), Synthea will retroactively assign an onset date, generate quarterly HbA1c measurements showing typical progression, assign antidiabetic medications in a realistic sequence, introduce comorbidities (hypertension, nephropathy) at appropriate times, and create hospital encounters for complications. A clinician reviewing the synthetic history sees a coherent disease progression, not random noise.
Clinical Trial Simulation
Pharmaceutical companies use synthetic patient data to simulate clinical trials before running expensive real-world studies. By generating cohorts of synthetic patients with realistic disease presentations, they can estimate enrollment timelines, predict dropout rates, forecast outcome distributions, and identify enrollment challenges.
Workflow: (1) Define trial inclusion/exclusion criteria and target patient population; (2) Generate large synthetic cohorts matching that population; (3) Run in-silico trial simulation by applying trial protocol (drug dosing, visit schedules, outcome measurements) to synthetic patients; (4) Analyze synthetic trial results to estimate power, expected effect sizes, and dropout patterns; (5) Design real trial informed by synthetic insights.
This approach has reduced time-to-IND (Investigational New Drug) applications and improved trial design efficiency at multiple biotech firms.
Medical Imaging Augmentation
Deep learning models for medical image analysis (radiology, pathology, ophthalmology) require thousands of annotated images. Synthetic image generation via GANs and diffusion models augments sparse real datasets. For rare conditions, synthetic images can be the primary training source.
Example—Retinal fundus images: Training a diabetic retinopathy detector requires thousands of annotated fundus photographs. Collecting and annotating real images is expensive and time-consuming. Researchers use conditional GANs trained on real fundus images to generate synthetic versions with varied disease severity levels, demographic characteristics, and image quality parameters. The synthetic images, while not perfect, augment the real dataset and improve model generalization, especially for underrepresented demographics.
Drug Discovery & Molecular Design
Generative models trained on chemical databases can propose novel molecules with desired properties (binding affinity, solubility, ADMET profiles). VAEs and diffusion models have accelerated molecular lead generation, shortening early-stage drug discovery by months.
Workflow: (1) Train generative model on corpus of known bioactive molecules; (2) Condition generation on desired properties (binding to target protein, low toxicity); (3) Sample novel synthetic molecules; (4) Validate synthetic structures for chemical feasibility (bond angles, charge states, synthetic accessibility); (5) Prioritize candidates for wet-lab synthesis and testing.
Regulatory Compliance & Data Sharing
Regulatory bodies increasingly ask for transparent evidence about how training and validation data were created. Synthetic data can support exploratory analysis, stress testing, and some parts of algorithm-performance evidence when it is clearly documented and validated, but it does not automatically satisfy FDA, HIPAA, or other regulatory requirements. Treat synthetic cohorts as regulated artifacts: document provenance, validation, privacy analysis, and the intended use boundary.
10.3 Financial Services
Financial institutions face a unique synthetic data problem: they have abundant real transaction data but cannot share it due to regulatory restrictions (PCI-DSS, GDPR, Basel III) and competitive sensitivity. Yet they need to collaborate with third-party vendors, conduct stress testing, and train fraud detection models. Synthetic transaction data has become essential.
Fraud Detection Training
Fraud is rare (typically 0.1–0.5% of transactions), making real fraud datasets highly imbalanced. Generative models trained on real (anonymized) transactions can oversample fraud examples and generate realistic synthetic fraud patterns, improving classifier training.
Workflow: (1) Train a conditional VAE or CTGAN on real transaction histories, conditioning on fraud/non-fraud labels; (2) Generate synthetic fraud transactions at desired rates; (3) Augment real training set with synthetic fraud; (4) Train fraud detector on balanced dataset; (5) Evaluate on held-out real test set.
The challenge: synthetic fraud may not capture novel fraud patterns that haven't been seen in training data. Successful institutions combine synthetic augmentation with anomaly detection (isolation forests, LOF) to catch novel fraud types.
Stress Testing & Market Simulation
Regulatory stress testing (CCAR, DFAST) requires banks to simulate loan portfolios under adverse economic scenarios. Generative models can simulate alternative macroeconomic paths, market conditions, and borrower behaviors, enabling banks to estimate portfolio risk without relying solely on historical scenarios.
Example—Mortgage portfolio stress test: A bank simulates 10,000 alternative economic futures by: (1) Generating synthetic interest rate paths using regime-switching stochastic models; (2) Generating synthetic unemployment rate paths correlated with rates; (3) Simulating borrower prepayment and default behavior conditional on economic conditions; (4) Aggregating portfolio losses across scenarios; (5) Reporting stress test capital requirements to regulators.
This approach provides regulators with evidence that capital buffers are adequate under extreme conditions.
Anti-Money Laundering (AML) Model Training
AML compliance requires detecting suspicious transaction patterns (structuring, rapid fund transfers, politically exposed persons). Institutions train transaction graphs and behavior models on real data but need balanced datasets of suspicious vs. clean transactions. Synthetic suspicious transactions enable training without exposing real customer data.
Credit Scoring & Risk Modeling
Credit risk models require balanced datasets of defaulted and non-defaulted loans. During economic booms, default rates drop, making it hard to train robust models. Generative models trained on historical default cohorts can generate synthetic default scenarios, improving model training during benign periods.
Vendor Collaboration & Outsourcing
Banks increasingly outsource model development to fintech vendors and consultancies. Rather than sharing real customer data, they provide vendors with synthetic datasets that preserve statistical patterns without identifying real customers. This accelerates vendor onboarding and reduces compliance friction.
10.4 Autonomous Vehicles & Robotics
Autonomous vehicles require millions of miles of driving data to train perception and planning models. Collecting real driving footage across all weather conditions, traffic patterns, edge cases, and failure modes is expensive and time-consuming. Synthetic simulation has become fundamental to AV development.
Synthetic Driving Scenes & CARLA
CARLA (Car Learning to Act) is an open-source simulator that generates photorealistic driving scenes with full control over environmental variables: weather (sunny, rainy, foggy), lighting, time of day, traffic patterns, pedestrian behavior, and vehicle dynamics. Developers can programmatically create edge cases—sudden lane changes, pedestrian jaywalking, adverse weather at intersections—that would be rare and dangerous to collect in the real world.
Workflow: (1) Define scenario (e.g., "pedestrian crossing at dusk with rain"); (2) Set map, weather, time parameters; (3) Generate synthetic sensor data (camera, LIDAR, radar) from simulator; (4) Collect ground truth annotations automatically; (5) Train perception model on synthetic data; (6) Transfer to real vehicle.
LIDAR Simulation & Synthetic Point Clouds
LIDAR (Light Detection and Ranging) is a primary sensor for autonomous vehicle localization and obstacle detection. Generative models trained on real LIDAR scans can synthesize point clouds for scenarios underrepresented in real data: dense urban environments, highway merges at night, weather-obscured visibility.
Conditional generative models can parameterize LIDAR scenes by environmental variables (visibility, traffic density, road geometry) and generate point clouds for any combination. This is vastly faster than collecting real data.
Edge Case Generation & Adversarial Scenarios
A key benefit of simulation is the ability to systematically generate edge cases: sudden traffic light changes, pedestrians behind parked cars, motorcycles weaving through lanes. Traditional test case generation is manual and incomplete. Generative models can automatically propose edge cases that are rare in real data but statistically plausible.
Sim-to-Real Transfer
A persistent challenge: models trained on synthetic simulator data often fail when deployed on real vehicles (sim-to-real gap). Domain adaptation techniques partially bridge this gap. Researchers apply style transfer to synthetic images to make them more photorealistic, use adversarial training to learn domain-invariant representations, or train models to be robust to distribution shift.
Practical workflow: (1) Train perception model on synthetic CARLA data with domain randomization (varying textures, lighting, object appearances); (2) Fine-tune model on small real dataset via transfer learning; (3) Deploy with uncertainty estimation and fallback to human control if confidence drops below threshold.
Robot Manipulation & Sim-to-Real
Robotic manipulation (grasping, assembly, pick-and-place) is similarly data-hungry. Simulators like Pybullet and MuJoCo can generate synthetic robot trajectories and images. Researchers train grasping networks on 100k+ synthetic grasp attempts, then transfer to physical robots.
10.5 Natural Language Processing
NLP models (chatbots, sentiment classifiers, machine translation) are typically trained on publicly available datasets. However, many organizations need domain-specific NLP: customer support chatbots trained on company-specific intents, clinical NLP systems trained on hospital notes (protected health information), or compliance NLP trained on contracts and regulations. Synthetic text generation has emerged as a practical solution.
Training Data for Chatbots & Intent Classification
Building a customer service chatbot requires annotated examples of customer utterances, intents, and expected system responses. Generating synthetic customer utterances at scale is far cheaper than hiring annotators.
Workflow: (1) Define intent ontology (e.g., "billing_inquiry," "order_status," "complaint"); (2) Write few-shot examples for each intent; (3) Use a large language model (GPT, Llama) to generate 1000+ synthetic utterances per intent, conditioning on intent label; (4) Optionally filter synthetic data for quality; (5) Train classifier on synthetic + small amount of real data; (6) Evaluate on held-out real test set.
In practice, synthetic training data often requires post-processing: removing nonsensical paraphrases, removing examples that closely replicate prompts, and deduplication.
Multilingual & Low-Resource Language Data
Machine translation and NLP for low-resource languages (e.g., Swahili, Tagalog) is hampered by sparse parallel data. Generative models can synthesize parallel corpora: given English text, generate synthetic translations into low-resource languages using a fine-tuned seq2seq model or LLM.
Caveat: Synthetic translations are often lower quality than human translations, with syntactic errors and semantic drift. However, they are useful for data augmentation and for training models that are further refined with limited human-translated data.
Content Moderation & Safety Data
Training content moderation classifiers (toxicity, hate speech, adult content) requires examples of harmful content. Collecting and annotating real examples raises ethical and legal concerns. Generative models can synthesize plausible (but fictional) harmful content for training purposes, reducing reliance on real harmful data.
Approach: Fine-tune a language model on a corpus of flagged content (or prompts describing harmful topics), then generate synthetic harmful examples. The synthetic examples are labeled as negative (harmful) and used to train classifiers. This avoids collecting and warehousing large corpora of real harmful content.
Language Model Fine-Tuning Data
Organizations often want to fine-tune language models for domain-specific tasks (legal document generation, medical note synthesis). Fine-tuning typically requires 100–10k labeled examples, but domain-specific labeled data is expensive. Synthetic data from domain-adapted base models can augment sparse real data.
10.6 Manufacturing & IoT
Manufacturing operations generate massive streams of sensor data—vibration, temperature, pressure, acoustic signals—from machinery. Predicting equipment failures (predictive maintenance) requires labeled datasets of normal and failing equipment. However, failures are rare; generating synthetic fault scenarios enables training robust anomaly detectors.
Predictive Maintenance via Synthetic Sensor Data
Modern factories seek to predict equipment failures before they occur, minimizing downtime and maintenance costs. Machine learning models for predictive maintenance require examples of sensor data leading up to failures. Generating synthetic degradation trajectories accelerates model training.
Workflow: (1) Collect historical sensor data (vibration, temperature) from equipment that has failed; (2) Identify temporal signatures preceding failures (e.g., increasing vibration amplitude in bearing pre-failure); (3) Train a generative model (LSTM-VAE, diffusion model) to synthesize sensor time series conditional on: (a) Normal operation; (b) Early degradation; (c) Late degradation / impending failure; (4) Generate synthetic time series spanning normal operation → gradual degradation → failure; (5) Train anomaly detector and remaining useful life (RUL) predictor on augmented dataset.
Sensor Network Simulation
IoT deployments involve thousands of heterogeneous sensors across geographies. Simulating realistic sensor data—including sensor drift, calibration drift, occasional sensor failures—enables testing monitoring algorithms without waiting for real failures.
Rule-based or physics-based simulators generate synthetic sensor data with configurable failure modes: sensor offset drift over time, sudden sensor failures, correlated sensor noise (e.g., multiple temperature sensors influenced by shared environment).
Anomaly Detection Training
Manufacturing anomalies (contamination, misalignment, unusual vibration) are rare in practice. Generating synthetic anomalies (often via rule-based perturbation or GAN-based methods) augments sparse real anomaly datasets, improving anomaly detector generalization.
10.7 Retail & E-Commerce
E-commerce companies operate with massive, highly sensitive customer behavior datasets. Customer purchase histories, browsing patterns, and preference models are competitive assets and privacy-sensitive. Synthetic customer behavior is valuable for testing recommendation systems, A/B testing, and building models without exposing real data.
Customer Behavior Modeling & Synthetic Cohorts
Recommendation systems require training on customer purchase sequences. Generative models trained on anonymized real purchase histories can synthesize realistic customer cohorts with varied demographics, preferences, and purchase patterns.
Use case—testing a new recommendation algorithm: A retailer develops a novel collaborative filtering method and wants to evaluate it before deploying to production. Using real customer data carries privacy risk and production impact. Instead, they generate synthetic customer cohorts with the same statistics as real customers (repeat purchase rate, preference distributions, seasonality), test the algorithm on synthetic data, and roll out only if synthetic results are promising.
A/B Testing & Counterfactual Simulation
A/B testing requires splitting traffic between variants and observing outcomes. For long-horizon conversions (e.g., cross-sell leading to subscription months later), real A/B testing can be slow. Generative models can simulate alternative user journeys: "What would user X have done under variant B?" This accelerates hypothesis testing.
Recommendation System Training
Collaborative filtering and content-based recommenders are trained on user-item interaction matrices. Synthetic interactions (user X would likely interact with item Y) augment sparse real interactions, especially for new users and items (the cold-start problem).
10.8 Government & Defense
Government agencies and defense departments operate under strict data security and classification requirements. Synthetic data enables research and training without exposing classified or sensitive information.
Census Data & Demographic Simulation
Census bureaus seek to publish rich demographic datasets enabling research without disclosing individual records. The U.S. Census Bureau has invested in synthetic data approaches, using Census PUMS (Public Use Microdata Sample) to train generative models that produce synthetic household and person records. Researchers can then analyze synthetic census data freely, without reidentification risk.
Intelligence & Surveillance Training
Intelligence agencies train analysts on threat detection, anomaly identification, and signal interpretation. Rather than using real classified intelligence, they generate synthetic intelligence scenarios (communications intercepts, transaction graphs, network traffic patterns) that preserve statistical structure without exposing actual operations or sources.
Cybersecurity Simulation & Network Traffic
Cybersecurity teams train intrusion detection and threat hunting models on network traffic. Generating synthetic network logs and traffic patterns enables testing security systems without exposing real operational networks.
Example—synthetic APT (Advanced Persistent Threat) simulation: A government agency simulates a sophisticated cyber attack campaign: (1) Model attacker behavior (reconnaissance, lateral movement, data exfiltration) as a sequence of network events; (2) Generate synthetic network logs incorporating realistic timing, packet patterns, and command-and-control communications; (3) Inject synthetic logs into SIEM (Security Information and Event Management) systems; (4) Test security team's detection and response procedures against synthetic threats.
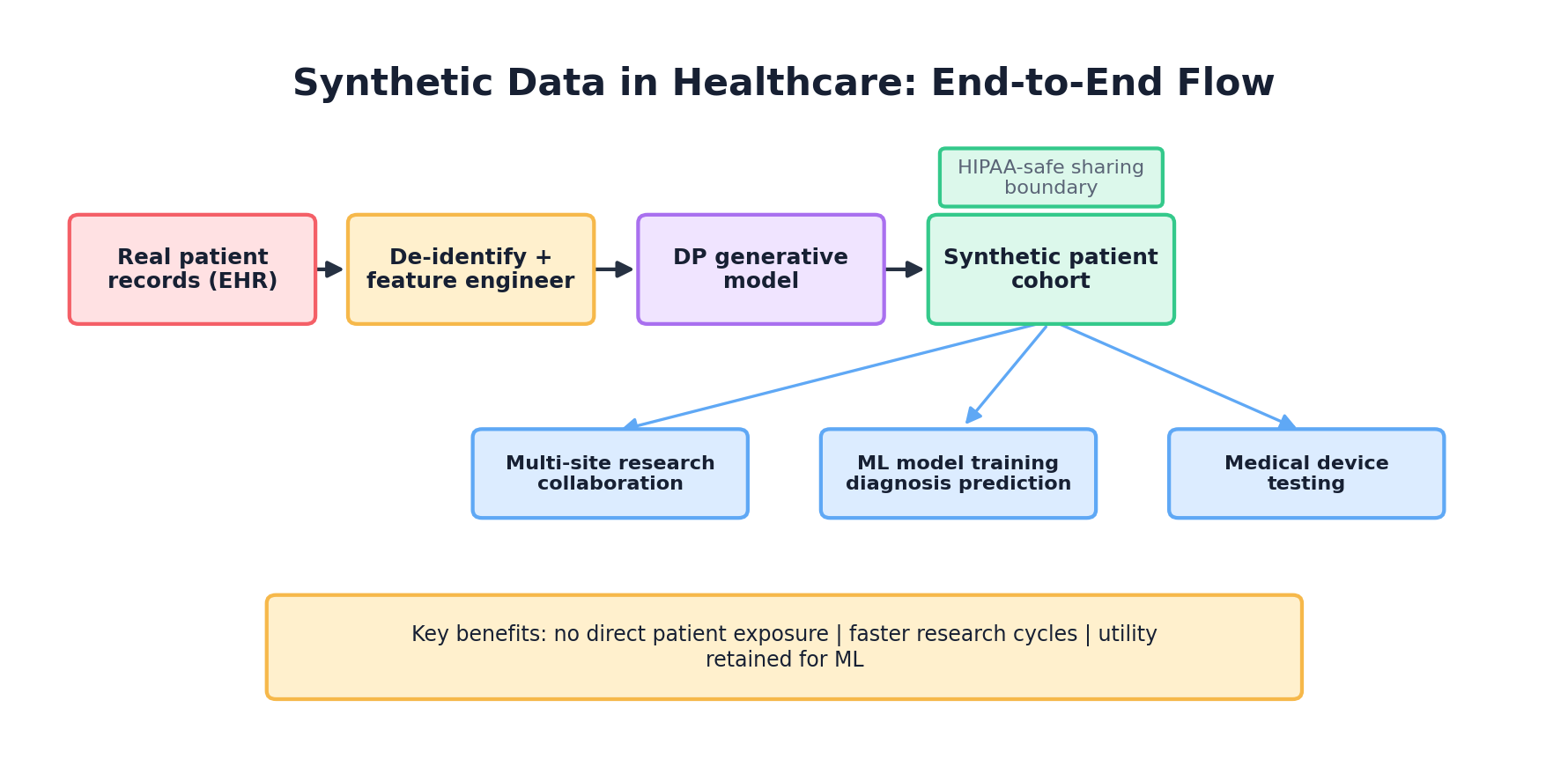
10.9 Case Study Deep Dive: Synthea in Production at a Hospital Network
To illustrate real-world complexities, we use a composite scenario based on common healthcare synthetic-data workflows. The numbers are illustrative rather than a documented deployment.
The Problem
A 50-hospital health system in the Midwest wanted to train a sepsis early warning model. Real patient data was available but fragmented across EHR systems, subject to HIPAA restrictions, and required IRB approval for each research project. Approval timelines ranged from 3–6 months. Multiple research teams had projects in queue, and each was spending weeks negotiating data use agreements and de-identification protocols.
The Approach
The health system's data science team adopted Synthea to generate a population-representative synthetic cohort of 100k patients with realistic disease prevalence, comorbidities, and temporal patterns. They configured Synthea with local demographics and disease prevalence estimates from their patient population. They generated:
- 50k patients with sepsis (varying severity and outcomes)
- 50k non-sepsis patients (controls)
Researchers could immediately access synthetic EHR data for method development. Once a promising model emerged, the team would validate against a small held-out real dataset (n=1000) with abbreviated IRB review.
Implementation Details
import json
import numpy as np
from synthea_wrapper import SyntheaGenerator
# Configure Synthea for local population
config = {
"state": "wisconsin",
"city": "milwaukee",
"population": 100000,
"age_distribution": [
{"age_range": "0-17", "percent": 0.20},
{"age_range": "18-44", "percent": 0.30},
{"age_range": "45-64", "percent": 0.30},
{"age_range": "65+", "percent": 0.20}
],
"race_distribution": {
"white": 0.48,
"black": 0.35,
"hispanic": 0.12,
"asian": 0.05
},
"disease_prevalence": {
"type_2_diabetes": 0.095,
"hypertension": 0.30,
"copd": 0.065,
"sepsis": 0.005 # 5 per 1000, oversampled
}
}
generator = SyntheaGenerator(config)
synthetic_patients = generator.generate()
# Filter for sepsis patients
sepsis_patients = [p for p in synthetic_patients
if p["conditions"]["sepsis"]]
control_patients = [p for p in synthetic_patients
if not p["conditions"]["sepsis"]]
print(f"Generated {len(sepsis_patients)} sepsis patients")
print(f"Generated {len(control_patients)} control patients")
# Export to FHIR format for EHR integration
generator.export_fhir("synthetic_patients_fhir.json")
Validation & Calibration
Before releasing synthetic data to researchers, the team validated the synthetic cohort against real population statistics:
- Age distribution matched the real patient population within the validation threshold chosen for the project
- Disease prevalence rates matched official epidemiological data (CDC estimates)
- Temporal patterns (seasonal respiratory infections, holiday-related ER visits) were realistic
- Comorbidity patterns matched known associations (diabetes + hypertension)
- Clinician review confirmed medication sequences and treatment patterns were appropriate
The team found some calibration issues: Synthea's default depression prevalence was lower than observed in their population. They adjusted the disease generator to increase depression assignments. Re-validation confirmed improved alignment.
Illustrative Results & Lessons
The synthetic-data workflow accelerated research:
- Method development time: 2–4 weeks (vs. 6–12 weeks waiting for IRB approval)
- Researchers could iterate rapidly without data access friction
- Models trained on synthetic data + validated on real data (n=1000) achieved 85–92% of real-data-only baseline performance
Key learnings:
- Calibration is critical: Generic Synthea requires tuning to local populations
- Clinician validation matters: Domain experts caught unrealistic patterns (e.g., medication sequences that violate clinical guidelines) that automated metrics missed
- Synthetic is not a silver bullet: For final validation, real data remains necessary. Synthetic data is best for development, not for publication-stage validation
- Governance and communication: Researchers initially distrusted synthetic data. Transparency about generation methods, validation results, and limitations built confidence
- Privacy benefits are asymmetric: Synthetic data provides privacy for the hospital (no real patient data leaves), but does not guarantee individual privacy if synthetic data is combined with external datasets (linkage attacks remain possible)
10.10 Case Study Deep Dive: CTGAN for Fraud Detection in Financial Services
In this composite scenario, a mid-sized payment processor faces a fraud detection challenge: its fraud dataset is severely imbalanced (0.3% fraud rate), limiting classifier training. The team uses CTGAN-style conditional generation to create candidate synthetic fraud transactions for augmentation and testing.
The Problem
The processor had 10 years of transaction history (500M transactions, 1.5M genuine frauds). Training fraud detection models on heavily imbalanced data leads to poor performance: classifiers learned to predict "not fraud" for everything (high accuracy, low recall on actual fraud). Standard approaches (class weighting, oversampling) helped but only modestly.
The Solution
They trained CTGAN on a balanced subset of real transactions (50% fraud, 50% legitimate, n=100k each) to learn patterns of both classes, then generated 500k synthetic fraud transactions to augment the training set.
import pandas as pd
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import Metadata
from sdv.sampling import Condition
# Real data: balanced fraud/non-fraud
real_fraud = pd.read_csv("fraud_transactions.csv") # n=50k
real_legit = pd.read_csv("legitimate_transactions.csv") # n=50k
# Combine and label
real_fraud["label"] = 1
real_legit["label"] = 0
balanced_data = pd.concat([real_fraud, real_legit])
# Train CTGAN on balanced data
metadata = Metadata.detect_from_dataframe(data=balanced_data)
synthesizer = CTGANSynthesizer(metadata, epochs=300, batch_size=500)
synthesizer.fit(balanced_data)
# Generate synthetic fraud
fraud_condition = Condition(num_rows=500000, column_values={"label": 1})
synthetic_fraud = synthesizer.sample_from_conditions(
conditions=[fraud_condition],
batch_size=5000,
max_tries_per_batch=500
)
# Combine for training
train_data = pd.concat([
real_fraud,
real_legit,
synthetic_fraud
])
# Train classifier
from sklearn.ensemble import GradientBoostingClassifier
X = train_data.drop("label", axis=1)
y = train_data["label"]
clf = GradientBoostingClassifier(n_estimators=100)
clf.fit(X, y)
Illustrative Results
On a held-out test set of 10k real transactions:
- Baseline (imbalanced real data only): 92% accuracy, 45% recall on fraud
- With synthetic fraud augmentation: 95% accuracy, 78% recall on fraud
In a real deployment, gains of this size would require strict holdout evaluation, calibration checks, and monitoring for false-positive cost. The point of the scenario is the workflow: synthetic fraud can help expose the classifier to more rare-event structure, but final claims must be made on real held-out transactions.
Lessons & Challenges
Challenge 1: Synthetic fraud drift. Fraudsters continuously evolve tactics. Synthetic fraud trained on 5-year-old data became obsolete as new fraud patterns emerged. The team implemented quarterly retraining on recent real fraud, ensuring synthetic generator tracked emerging patterns.
Challenge 2: Validation against real data. Early versions of synthetic fraud contained unrealistic patterns (e.g., synthetic transactions with amounts and merchant categories that never occur together in reality). The team added domain constraints to CTGAN training and post-hoc filtering to ensure synthetic transactions matched known transaction patterns.
Challenge 3: Regulatory acceptance. The processor needed to justify synthetic data usage to external auditors (Visa, Mastercard) and regulators (FinCEN). They provided: detailed CTGAN methodology documentation, validation results showing synthetic fraud statistics matched real fraud, and holdout test results demonstrating production performance.
10.11 Lessons Learned Across Industries
Examining these case studies and broader industry trends reveals recurring patterns about what works and what doesn't with synthetic data.
What Works
- Clear use case definition: Synthetic data works best when the problem is well-defined: augmenting imbalanced classes, enabling rapid model iteration, sharing data across organizational boundaries. Vague goals ("improve our ML") lead to wasted effort.
- Domain-informed generation: Synthetic data quality improves dramatically when domain experts guide generation. Healthcare Synthea works because it incorporates medical knowledge. Manufacturing sensor simulation works because engineers specify physics constraints. Generic generative models (CTGAN, GANs) applied naively often fail.
- Validation before deployment: Organizations that validate synthetic data against real data before deploying models avoid embarrassing failures. Validation should be quantitative (distributional tests, statistical tests) and qualitative (expert review).
- Continuous retraining: Synthetic data generators degrade as real distributions shift. Successful organizations retrain generators quarterly or annually, adapting to new patterns (new disease prevalences, new fraud tactics, new customer behaviors).
- Hybrid workflows: The most mature organizations use synthetic data for iteration and development, then validate on held-out real data. Synthetic data is a tool for efficiency, not a replacement for real data.
Common Pitfalls
- Overstating privacy claims: Synthetic data is not automatically privacy-preserving. Many organizations release synthetic data without auditing membership inference or linkage risks. The FDA and European regulators increasingly scrutinize privacy claims.
- Ignoring distribution shift: Models trained on older synthetic data fail when deployed against new real data. Continuous monitoring and retraining are essential.
- Treating synthetic as a substitute for real data: Some organizations attempt to build models entirely on synthetic data, skipping real validation. This usually fails—synthetic data is an augmentation tool, not a replacement.
- Insufficient quality assessment: Organizations sometimes deploy synthetic data generators without rigorous validation. The result: models trained on synthetic data with unrealistic statistical properties, poor real-world performance.
- Underestimating implementation burden: Production synthetic data pipelines require versioning, lineage tracking, ongoing monitoring, and governance. Many organizations underestimate this operational overhead.
Industry Maturity Levels
Level 1 (Exploratory): One-off synthetic data generation for specific projects. Limited governance, validation is ad-hoc. Common in startups and early-stage research.
Level 2 (Operational): Established pipelines generating synthetic data regularly. Versioning and validation are formalized. Data governance is developing. Common in mid-sized enterprises.
Level 3 (Strategic): Synthetic data is a core part of data strategy. Full governance, monitoring, and continuous improvement. Privacy audits are routine. Regulatory compliance is built-in. Common in large enterprises and institutions with mature ML infrastructure.
Progress from Level 1 to Level 3 typically requires 2–3 years, significant investment in tooling and processes, and organizational commitment from leadership.
10.12 Conclusion: The Role of Synthetic Data in Modern Enterprise
Synthetic data has transitioned from research novelty to operational necessity across industries. Healthcare organizations use it to accelerate drug discovery and clinical research. Financial institutions use it to train fraud detectors and stress-test portfolios. Autonomous vehicle companies use it to develop perception systems safely. Governments use it to enable research under classification constraints.
The common thread: synthetic data solves friction points. It enables rapid iteration without waiting for data access approvals. It allows sharing of sensitive data patterns without exposing individuals. It generates edge cases and failure modes that would be rare or dangerous to collect in the real world. It augments imbalanced datasets. It accelerates development timelines.
However, synthetic data is not magic. It requires careful generation informed by domain knowledge, rigorous validation, and continuous monitoring. Privacy claims must be audited, not assumed. Quality degrades as real distributions shift. Synthetic data augments real data workflows; it does not replace them.
As generative AI advances (larger language models, more capable vision models, better diffusion models), the quality and diversity of synthetic data will improve. Simultaneously, privacy risks and concerns about AI-generated content authenticity will intensify. The organizations best positioned to benefit will be those that invest in governance, validation infrastructure, and cross-functional collaboration between domain experts and data scientists.
References and Further Reading
- (2018). Synthea: An Approach, Method, and Software Mechanism for Generating Synthetic Patients and the Synthetic Electronic Health Care Record. Journal of the American Medical Informatics Association, 25(3), 230-238. academic.oup.com/jamia/article/25/3/230/4821152
- (2020). Generation and Evaluation of Synthetic Patient Data. BMC Medical Research Methodology. bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-020-00977-1
- (2019). Modeling Tabular Data using Conditional GAN. Advances in Neural Information Processing Systems. arxiv.org/abs/1907.00503
- (2002). SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research, 16, 321-357. jair.org/index.php/jair/article/view/10302
- (2026). Methods for De-identification of PHI. HHS HIPAA Guidance. hhs.gov/hipaa/for-professionals/privacy/special-topics/de-identification
- (2023). Assessing the Credibility of Computational Modeling and Simulation in Medical Device Submissions. FDA Guidance. fda.gov/regulatory-information/search-fda-guidance-documents/assessing-credibility-computational-modeling-and-simulation-medical-device-submissions
- (2022). Synthetic Data - What, Why and How? arXiv preprint. arxiv.org/abs/2205.03257