Chapter 12 — The Future of Synthetic Data
1. Where We Are Today
By this point in the book we have covered the core techniques, the tooling ecosystem, and the industries where synthetic data is already being deployed. Before we turn to two specialized topics that round out the practitioner's toolkit — time series (Chapter 13) and synthetic-data operations (Chapter 14) — it is worth stepping back to survey the frontier. Synthetic data has moved from research curiosity to practical tooling in many sectors. Mature tools exist, production deployments are growing, and business cases are clearer than they were a few years ago. Yet the landscape remains volatile, with fundamental questions still unsettled and vast unexplored territory ahead.
The maturity we see today is real but incomplete. Practitioners can generate useful tabular data and, when using formal privacy mechanisms, attach explicit privacy budgets to the generation process. Computer vision systems benefit from synthetic training data at scale. Natural language models leverage synthetic instructions for fine-tuning. These workflows are no longer purely experimental, but their reliability depends heavily on domain, data quality, validation design, and governance. Major cloud providers and specialized vendors offer synthetic data services. Open-source frameworks have stabilized in some areas, especially tabular synthesis and evaluation, while multimodal and agentic generation remain more fluid.
Yet "maturity" in synthetic data does not mean "solved." The fundamentals work in many settings, growth is rapid, and governance is still catching up. Most practitioners operate with implicit assumptions about quality, privacy, and fairness that rarely surface until something breaks. General AI governance standards exist, but they do not yet provide a universal certificate that a particular synthetic dataset is private, fair, or useful for a downstream task. The economics of synthetic data also remain opaque, with pricing models that often track compute or platform access rather than realized value.
This chapter examines what comes next—not predictions meant to be prescriptive, but trajectories we should watch, tensions we must resolve, and opportunities being actively seized right now. The future of synthetic data is being written by researchers, entrepreneurs, and practitioners experimenting at the edges. Our task is to understand the landscape they're building.
2. Foundation Models & Synthetic Data
Emerging Actively DeployedThe arrival of large foundation models has fundamentally altered how we think about synthetic data generation. For years, synthetic data was positioned as a supplement to real data—a gap-filler for missing examples, rare classes, or privacy-constrained domains. Foundation models invert this relationship: they are increasingly used as generators of synthetic training data, sometimes yielding better performance than original datasets.
Consider the mechanics. A pre-trained language model like GPT or Llama understands statistical patterns in text at a scale that captures genuine nuance. When directed to generate synthetic training examples—whether instruction-response pairs, classification instances, or structured outputs—it doesn't merely duplicate training data. It extrapolates coherently in directions the model has learned are plausible. For many tasks, synthetically generated examples from a strong foundation model now outperform human-annotated data, particularly when the task specification is clear.
This has profound implications. First, it democratizes access to data. Teams without large labeled datasets can now bootstrap training sets by prompting a foundation model, iterating on quality, and using the results to fine-tune a smaller task-specific model. The constraint shifts from "we can't afford to label 100K examples" to "can we specify the task clearly enough for a generator to produce useful examples?"
Second, it reshapes the pre-training paradigm. Researchers are discovering that mixing synthetic data into pre-training corpora—carefully curated synthetic examples interspersed with real-world text—can improve downstream task performance without diluting model generalization. This is not free scaling; the quality and diversity of synthetic data matter intensely. But it means pre-training pipelines can increasingly optimize for capability rather than merely for scale of raw text.
The challenge ahead is quality at scale. Foundation models are powerful but prone to hallucination, inconsistency, and subtle bias amplification. When used as generators, these flaws scale too. A foundation model might produce synthetic examples that are statistically plausible but semantically nonsensical, or that encode subtle distributional skews invisible to human review. The field is still learning how to characterize these failure modes, detect them automatically, and bound their impact on downstream tasks.
Another frontier is synthetic data for pre-training itself. Some researchers propose that foundation models could be pre-trained partly on data synthesized by smaller, weaker models in a structured pipeline—a form of curriculum learning at massive scale. The efficiency gains could be substantial. But the risks are equally large: if synthetic pre-training data encodes systematic biases, those biases become foundational, amplifying through all downstream applications.
3. Synthetic-Data-First Development
Paradigm ShiftA quiet but significant inversion is occurring in how teams approach data-driven product development. Traditionally, the sequence was: identify task, collect real data, label it, train models, iterate based on results. Real data was the foundation; synthetic data was contingent.
A growing cohort of teams is reversing this: start by designing synthetic data that exhibits the properties you need, use that to explore model architectures and training approaches, then—and only then—collect real data to validate and refine. This is not a replacement for real data validation; it's a reordering of the pipeline that yields surprising efficiency gains.
The logic is straightforward. Synthetic data can be generated instantly, in any quantity, with precisely controlled properties. You can ask: "What if we had 10x more data?" or "What if class imbalance were this severe?" or "What if outliers looked like this?" These questions become computational, not logistical. You iterate on data design much faster than you could on real data collection.
This inversion has revealed something important: data quality and task specification are often conflated. Many teams assumed they needed larger datasets when they actually needed clearer task definitions. By designing synthetic data first, you're forced to specify exactly what your model should learn, in exhaustive detail. This clarity is itself valuable, independent of whether the synthetic data is ultimately useful for training.
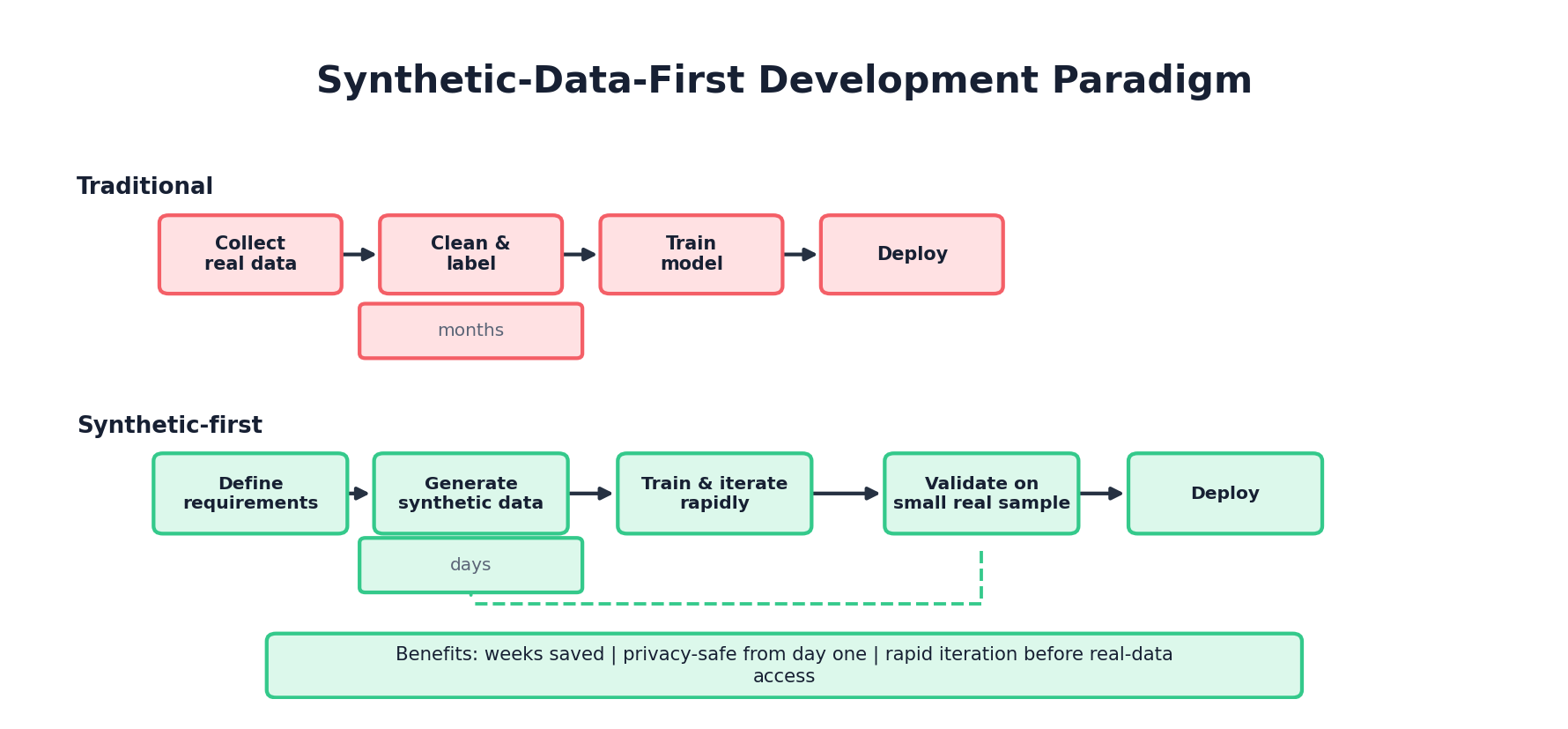
Early adopters report that synthetic-data-first workflows reduce time from problem statement to working prototype by 30-50%. The approach is particularly effective for:
- Rare event detection—you can synthesize failures, anomalies, and edge cases that occur too rarely in real data
- Underspecified problems—where the task definition is still fluid, synthetic data forces you to nail down requirements
- Privacy-critical domains—where real data collection is regulated or sensitive; start with synthetic to validate approach, then move to real data
- Novel product features—where no historical data exists yet; synthetic data lets you prototype before launch
As this paradigm matures, expect to see new tools and frameworks designed around it. DAG-based data specification languages. Formal methods for validating that synthetic data exhibits intended properties. Automated benchmarks that measure how well synthetic data prepares you for real-world performance. The infrastructure is still nascent, but investment is accelerating.
4. Multi-Modal Synthesis
Rapidly AdvancingMost synthetic data discussions focus on single modalities: tabular data, text, or images. Yet many real-world problems require paired multi-modal data where the relationships between modalities are semantically meaningful and non-trivial.
Consider autonomous vehicles: you need LiDAR point clouds paired with high-resolution camera images, all synchronized to ground-truth labels (traffic lights, pedestrian positions, lane markings). The spatial and temporal consistency across modalities is essential; random pairing of synthetic LiDAR with synthetic images is useless. Or medical imaging: CT scans paired with radiologist reports, where the report must accurately describe the visual findings. Or recommendation systems: user behavior sequences paired with product descriptions, where the pairing should reflect realistic query-item relevance.
Generating convincing multi-modal synthetic data is harder than it sounds. You can generate text and images independently using separate models, but their coherence and alignment degrade rapidly. A foundation model might generate a plausible image of "a cat on a rug" but pair it with a caption like "a painting of abstract geometry." The errors are individually realistic but jointly nonsensical.
Recent progress uses joint generative models—architectures that model the distribution across all modalities simultaneously, respecting their correlations. Diffusion models show particular promise here. They can generate multiple modalities in lockstep, with cross-attention mechanisms ensuring alignment. A recent paper demonstrated synthetic 3D scenes (visual, depth, semantic labels) with consistent geometry across all modalities, good enough to train downstream models that transfer to real scenes.
The frontier is scaling this to complex, long-horizon scenarios. Generating a 10-second video with synchronized audio, object trajectories, and natural language commentary is beyond current capabilities. But the direction is clear, and the applications are substantial. Synthetic multi-modal data could unlock training for embodied AI, robotic systems, and understanding tasks where practitioners currently struggle to gather sufficient real data.
5. Agentic Data Generation
Experimental, High PotentialA new class of systems is emerging where AI agents autonomously design, generate, evaluate, and refine synthetic datasets. Rather than a human specifying "generate 10,000 examples of X," an agentic system would receive a task specification and a target performance metric, then iterate to discover what synthetic data distribution best achieves that metric.
The loop works like this:
- Specification: Define a task and a performance target. "Train a classifier to detect credit card fraud with 95% precision on real test data."
- Generation: An agent generates candidate synthetic datasets based on prior knowledge, heuristics, or learned strategies.
- Evaluation: Train models on synthetic data, evaluate on held-out test data, measure gap between synthetic and real performance.
- Refinement: The agent observes where synthetic data most hurt real performance (often a "domain gap" signal) and refines the data generation strategy.
- Iteration: Repeat until performance converges or resource budgets are exhausted.
This is qualitatively different from hand-tuned synthetic data pipelines. The agent discovers strategies that humans might not naturally try. For instance, it might discover that for a fraud detection task, synthetic data is most useful not for the main class distribution (where historical real data is ample) but for boundary cases—transactions that sit at the threshold of detection heuristics. By concentrating synthetic data generation there, it unlocks outsized gains.
Early research systems show promise on structured tabular tasks. A system trained to generate synthetic data for a classification task discovered that bimodal distributions in sensitive features led to better real-world performance than uniform distributions—a non-obvious insight. But scaling to high-dimensional, long-horizon, or partially observable domains remains open.
The potential impact is enormous. If agentic systems can autonomously optimize synthetic data quality, entire domains become more tractable. Rare event prediction, where data is sparse and expensive to collect, could be solved by having an agent run overnight to discover optimal synthetic data distributions. Privacy-constrained settings, where you can't experiment freely with real data, could benefit from agents optimizing synthetic proxies.
6. Regulatory Evolution
Already HereRegulatory frameworks have not kept pace with synthetic data deployment. Most privacy regulations (GDPR, CCPA, HIPAA) were written with real personal data in mind. They treat synthetic data as derivative—a transformed version of real data that might or might not be adequately anonymized. The legal status of synthetic data remains ambiguous in many jurisdictions.
This ambiguity is narrowing, but unevenly. Under GDPR, the core question remains whether a person is identified or identifiable after considering reasonably likely means of re-identification; synthetic data derived from real personal data must therefore be assessed case by case. HIPAA does not create a special synthetic-data exemption: teams still rely on de-identification pathways such as Safe Harbor or Expert Determination, plus additional privacy analysis when synthetic generation was trained on protected data. Financial and healthcare regulators may accept synthetic data for testing, stress analysis, or exploratory evidence, but they still expect documentation, validation, and a clear intended-use boundary.
Several patterns are emerging:
- Disclosure expectations: If a model or analysis depends materially on synthetic data derived from real data, reviewers often expect provenance documentation: what source data was used, how generation was performed, and what validation was run.
- Certification workflows: Governance teams are experimenting with privacy and utility scorecards, but there is not yet a broadly accepted regulatory safe harbor for synthetic data that passes a standard test suite.
- Purpose limitation: Synthetic data generated for one purpose may not be appropriate for another without fresh validation. This is particularly important in healthcare, finance, and regulated public-sector settings.
- Residual disclosure risks: Privacy reviews increasingly ask teams to quantify residual risks such as membership inference, attribute inference, and linkage, even after synthetic generation. "Synthetic" is not enough; the release needs evidence.
Looking forward, expect governance to distinguish more carefully between fully simulated data, partially synthetic data, augmented data, and model-generated derivatives of personal data. Management-system standards such as ISO/IEC 42001 can help organizations govern AI systems, but dataset-level certification still requires concrete evidence: provenance, utility validation, privacy testing, bias analysis, and accountability for downstream use.
7. Synthetic Data Marketplaces
Emerging InfrastructureIf synthetic data can be created by models rather than collected from users, a surprising possibility emerges: synthetic data as a commodity, bought and sold in markets much like cloud compute or stock data. Several platforms are already building this infrastructure.
The proposition is straightforward: a team with a specialized generative capability (e.g., a foundation model fine-tuned on high-quality medical imaging) could offer synthetic data as a service. Customers specify requirements—"I need 50,000 synthetic chest X-rays with documented pathologies"—and the system generates customized datasets on demand. Pricing is per-example, per-dataset, or per-unit-of-compute.
Early movers include platforms offering tabular synthetic data for machine learning, synthetic user behavior for recommendation systems, and synthetic code for training programming models. Adoption is growing, particularly in sectors where real data is expensive (healthcare, finance) or where custom generation at scale is technically valuable (computer vision).
Several challenges remain unresolved:
- Quality certification: How do customers verify that purchased synthetic data is actually useful for their task? Marketplaces need transparent, task-agnostic quality metrics.
- IP and liability: If synthetic data causes downstream harm (e.g., a model trained on synthetic data makes an incorrect decision), who is liable? The generator, the platform, or the customer?
- Customization vs. reuse: Is synthetic data most valuable when custom-generated for a customer's exact needs, or when standardized and reusable? Economic models differ radically.
- Provenance and licensing: What rights do customers have to use, modify, or redistribute synthetic data they purchased?
Despite these challenges, the market is moving. It is reasonable to expect continued consolidation: established cloud providers integrating synthetic data services, specialized startups being acquired, and more explicit norms around data quality and licensing. Whether synthetic data as a service becomes as routine as cloud storage depends on validation standards, customer trust, and liability allocation.
8. Quality & Trust Certification
Active ResearchAs synthetic data becomes ubiquitous, trust becomes paramount. How do you know if synthetic data is actually good? Current approaches rely on hand-wavy metrics: "fidelity" (how well the synthetic data matches real data), "diversity" (coverage of the space), and "utility" (downstream task performance). These are intuitive but crude.
The field is moving toward more rigorous certification frameworks:
| Dimension | What It Measures | Status |
|---|---|---|
| Privacy Certification | Bounds on membership inference, attribute inference, and re-identification risk | Active governance area; no universal dataset-level certificate |
| Fidelity Metrics | Statistical similarity: KL divergence, Wasserstein distance, chi-squared tests | Mature for tabular; emerging for images, sequences |
| Bias Detection | Systematic differences between synthetic and real data in subgroups | Frameworks exist, but detection remains hard |
| Task Utility | Downstream model performance on real test sets when trained on synthetic | Highly task-specific; no universal metric yet |
| Distribution Shift Robustness | How well models trained on synthetic data handle real-world distribution shift | Emerging; critical for deployment |
Major standards bodies are beginning to shape the surrounding governance environment. NIST's AI Risk Management Framework gives organizations a vocabulary for mapping, measuring, managing, and governing AI risk. ISO/IEC 42001 defines an AI management system. These are important building blocks, but they do not by themselves certify that a specific synthetic dataset is useful, private, or unbiased.
A critical frontier is dynamic certification. Synthetic data does not degrade over time in the same way real data ages, but its utility for new tasks can be hard to predict. Research into synthetic-data test suites - standard benchmarks that evaluate quality across multiple dimensions - is accelerating. A realistic future certificate may not say "this data is good"; it may say, more narrowly, "on these tasks, under these assumptions, this release meets these measured utility, privacy, and bias thresholds."
9. Open Problems & Research Frontiers
Fundamental QuestionsDespite significant progress, several fundamental problems remain unresolved. These are not engineering challenges; they're conceptual frontiers where breakthrough insights are still needed.
Distribution Shift Detection
Synthetic data is almost always drawn from a different distribution than real data, due to generator bias, training artifacts, or fundamental limitations in how generative models work. This distribution shift is often subtle—statistically significant in high dimensions but imperceptible to human review. Models trained on synthetic data can experience sudden performance collapse on real data due to this shift.
The unsolved problem: how do you detect and quantify distribution shift between synthetic and real data without access to real data? In many practical scenarios, you have synthetic data available (cheap, instant) and want to know if it's useful before investing in expensive real data collection. Current approaches require either labeled real data for validation or strong distributional assumptions. Better methods could unlock synthetic data as a true exploration tool.
Causal Synthetic Data
Most synthetic data generation optimizes for matching marginal and conditional distributions. But real-world phenomena are generative—they arise from causal mechanisms. Synthetic data that respects the causal structure of real data could enable counterfactual reasoning, policy optimization, and robustness to interventions in ways that distributionally-matched data cannot.
Generating synthetic data that is both distributionally faithful and causally valid remains largely open. Some recent work combines causal graphs with generative models, but scaling to high-dimensional domains (e.g., images, video) with complex causal structures is unsolved. This is a frontier where even fundamental definitions are still settling.
Synthetic Data for Reasoning
Language models trained on synthetic instructions show strong performance on in-distribution tasks but struggle with novel reasoning problems. Why? Likely because purely synthetic instruction data fails to capture the long-tailed distribution of reasoning patterns humans actually exhibit. Generating synthetic data that teaches reasoning—that is, synthetic datasets where simple statistical patterns won't solve the problem, forcing models to develop generalizable reasoning skills—remains largely unsolved.
This is critical for advancing foundation models. Scaling laws appear to be flattening; adding more raw data helps less and less. But synthetic data designed to target reasoning gaps could unlock continued improvements. The research question is: how do you characterize and synthesize the patterns that actually teach reasoning?
Evaluation Gaps
Current benchmarks for synthetic data utility are task-specific and often designed for specific domains. We lack universal benchmarks—standard test suites that comprehensively evaluate whether synthetic data will be useful for diverse downstream tasks. Building these benchmarks is an open challenge. Unlike accuracy benchmarks (where you have ground truth labels), synthetic data utility benchmarks require understanding task diversity, distribution shift, and real-world performance implications.
Other open problems include: synthetic data for long-horizon sequential decision-making, synthetic data for domains with continuous state spaces, privacy-synthetic data tradeoffs under different adversarial models, and integration of synthetic data into active learning and human-in-the-loop pipelines.
10. A Call to Action
If you've read this far, you occupy a privileged position. Synthetic data is moving from research to production, from exotic to routine. The next two years will determine much about how the field evolves. Here's what you can do:
For Practitioners
- Start experimenting now. Pick a non-critical use case—a classification task, a regression problem, something where real data already exists but is limited or expensive. Build a synthetic data pipeline. Measure downstream utility rigorously. Document what works and what doesn't. Your findings will be ahead of most of the industry.
- Invest in quality metrics. Don't just generate synthetic data; measure it. Track distribution divergence, evaluate downstream performance systematically, and build intuition for what makes synthetic data useful in your domain. This expertise will be increasingly valuable.
- Engage with standards. Whether through professional organizations, industry consortia, or regulatory bodies, help shape emerging standards for synthetic data. Your voice as a practitioner matters now, before standards ossify. Contributing to open-source synthetic data tools and benchmarks amplifies your impact.
- Build for governance. Assume your synthetic data pipelines will eventually face audits, regulatory scrutiny, or legal challenges. Design for transparency: log what synthetic data was used, how it was generated, what validation it underwent. Future-proof your systems now.
For Researchers
- Focus on fundamentals. The field needs work on distribution shift detection, causal synthesis, and reasoning-focused data generation more than it needs another marginal improvement on fidelity. These foundational problems will unlock entire application areas.
- Build benchmarks. Synthetic data evaluation is fragmented. Proposing and championing a comprehensive benchmark suite—evaluated on diverse domains, compared against competing approaches—would be an outsized contribution.
- Study integration with real-world workflows. Much research on synthetic data happens in isolation. Research on how synthetic data integrates with human experts, active learning, domain adaptation, and continuous learning would bridge the gap between research and practice.
- Investigate adversarial robustness. As synthetic data becomes pervasive, adversaries will target it. Research on adversarial attacks and defenses in synthetic data generation—and on how to detect when synthetic data has been poisoned—is underexplored and critical.
For Organizations and Leaders
- Allocate resources strategically. Synthetic data is not a magic solution, but it is a capability multiplier in specific contexts: privacy-constrained domains, rare event prediction, new product exploration. Identify where synthetic data creates the most value in your organization and invest there first.
- Build institutional knowledge. Teams that develop deep expertise in synthetic data—understanding its strengths, limitations, and organizational fit—will outcompete those treating it as a commodity. Invest in training, communities of practice, and knowledge sharing.
- Shape industry standards. If you have resources and influence, participate in standards development. The organizations that help define synthetic data quality, privacy, and licensing frameworks will benefit from those standards for years.
- Invest in tooling. The infrastructure for synthetic data pipelines is still fragmented. Opportunities exist to build internal platforms, contribute to open-source ecosystems, or fund companies addressing persistent pain points. Better tools will accelerate adoption and surface new use cases.
For Everyone
- Stay informed. The field is evolving rapidly. Follow research advances, track industry deployments, and engage with communities. The synthetic data ecosystem includes excellent resources: conferences, workshops, journals, and open-source projects. Staying current takes modest effort and yields substantial returns.
- Think critically about claims. Inevitably, some practitioners and vendors will oversell synthetic data—claiming it solves problems it doesn't, guaranteeing quality it can't provide, or promising privacy it doesn't deliver. Healthy skepticism and an understanding of limitations are essential.
- Contribute to openness. Publishing negative results, open-sourcing tools, and sharing lessons learned accelerates the entire field. The most valuable contributions are often not novel algorithms but transparent documentation of what works, what doesn't, and why.
Looking Ahead
For years, synthetic data was the province of specialists. Over the next several years it is likely to become a standard option in many mature machine learning organizations, especially where privacy, rare events, simulation, or rapid prototyping matter. The infrastructure is being built. The standards are beginning to crystallize. The use cases are multiplying. The regulatory and ethical frameworks are still being negotiated.
That does not mean the field has been "solved." The opposite is true. Synthetic data has only begun to deliver on its promise. The most impactful applications are likely still being imagined, and the most important research breakthroughs are ahead. The future of machine learning is not purely real data at massive scale — it is a synthesis: a careful orchestration of real and synthetic data, human expertise and automated generation, privacy protection and utility optimization.
The trends surveyed here — foundation-model-driven synthesis, agentic generation, multi-modal alignment, convergence of regulation — apply broadly to tabular and text use cases. The next two chapters narrow the lens. Chapter 13 tackles the particular challenges of time series and sequential data, where temporal dependencies break most of the assumptions behind the generators we have discussed so far. Chapter 14 then looks at the operational side: how to deploy, monitor, and govern synthetic-data pipelines in production. Together they close the loop between the forward-looking ideas in this chapter and the practical plumbing needed to act on them.
References and Further Reading
- (2022). Synthetic Data - What, Why and How? arXiv preprint. arxiv.org/abs/2205.03257
- (2022). A Framework for Auditable Synthetic Data Generation. arXiv preprint. arxiv.org/abs/2211.11540
- (2023). Self-Instruct: Aligning Language Models with Self-Generated Instructions. Association for Computational Linguistics. arxiv.org/abs/2212.10560
- (2023). Stanford Alpaca: An Instruction-following LLaMA Model. Stanford Center for Research on Foundation Models. crfm.stanford.edu/2023/03/13/alpaca
- (2023). Textbooks Are All You Need. arXiv preprint. arxiv.org/abs/2306.11644
- (2022). High-Resolution Image Synthesis with Latent Diffusion Models. IEEE/CVF Conference on Computer Vision and Pattern Recognition. openaccess.thecvf.com
- (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0). NIST. nist.gov/itl/ai-risk-management-framework
- (2023). ISO/IEC 42001: Artificial Intelligence Management System. ISO. iso.org/standard/42001
- (2026). Methods for De-identification of PHI. HHS HIPAA Guidance. hhs.gov/hipaa/for-professionals/privacy/special-topics/de-identification
- (2026). Anonymization Topic Page. European Data Protection Board. edpb.europa.eu/our-work-tools/our-documents/topic/anonymization_en