Chapter 14: Synthetic Data Ops
14.1 Generation Is Not Deployment
A synthetic dataset is not production-ready because a model can generate realistic rows. In practice, the hard part starts after the first convincing sample. Teams must answer operational questions: Which source snapshot produced this release? Which generator version and parameter set were used? What privacy budget was consumed? Which tests passed, and who approved the release? Without those answers, synthetic data becomes a high-risk artifact that is difficult to trust, difficult to reproduce, and difficult to roll back.
This is why synthetic data needs its own operational discipline. Traditional data engineering focuses on ingestion, transformation, and storage. Machine learning operations focuses on model training and serving. Synthetic Data Ops sits between them: it governs how synthetic datasets are generated, validated, versioned, published, monitored, and retired.
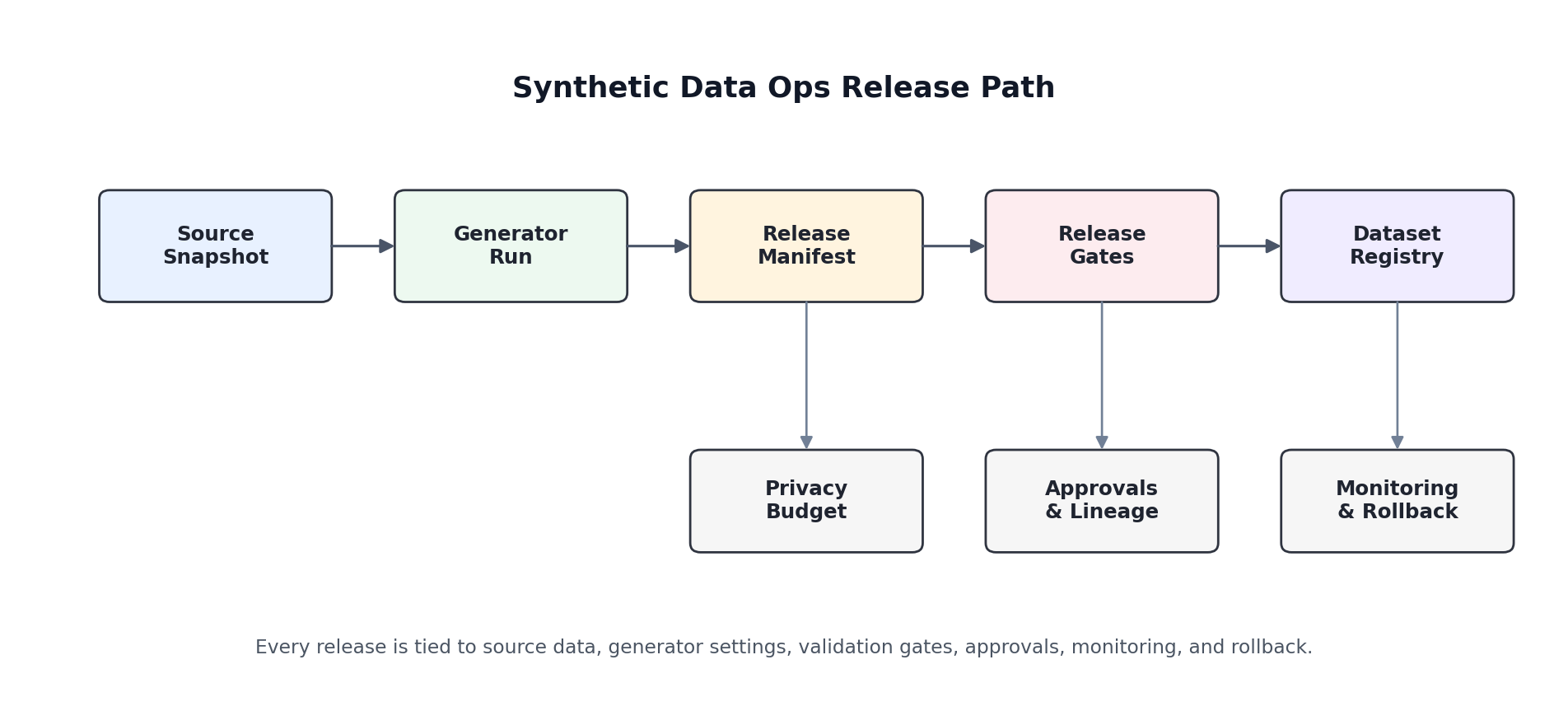
14.2 The Release Manifest
The simplest useful operational pattern is a release manifest. This is a structured record describing what was generated, from what source, by which model, under which constraints, and with what test results. A manifest turns an opaque CSV into a traceable release.
release_manifest = {
"dataset_name": "fraud_synthetic_v2026_04",
"source_snapshot": "warehouse://fraud/train/2026-04-01",
"generator": {
"family": "CTGANSynthesizer",
"version": "sdv-1.x",
"parameters": {
"epochs": 300,
"batch_size": 500
}
},
"constraints": [
"label in {0,1}",
"amount >= 0",
"transaction_time is timezone-normalized"
],
"privacy": {
"mechanism": "empirical audit",
"epsilon": None,
"nearest_neighbor_threshold": 0.18
},
"quality_gates": {
"detection_auc_max": 0.78,
"tstr_auc_min": 0.84,
"schema_validation": True,
"subgroup_checks": ["country", "merchant_category"]
},
"approvals": {
"data_owner": "fraud-platform",
"reviewer": "privacy-team"
}
}The exact schema does not matter as much as the habit. Once every release carries a manifest, you can diff releases, audit regressions, and reconstruct the logic behind a bad dataset after the fact.
14.3 Release Gates
Synthetic data should not be published directly from model output. It should pass through a set of release gates. The gates do not need to be complicated, but they do need to be explicit.
- Schema gates: column names, types, nullability, key uniqueness, and referential integrity.
- Quality gates: marginal similarity, correlation preservation, task utility, and failure-rate thresholds.
- Privacy gates: nearest-neighbor checks, memorization audits, attack simulations, or formal privacy accounting.
- Subgroup gates: verify fidelity and utility across protected groups, regions, or business segments.
- Policy gates: intended use, retention policy, and access-control classification.
Teams frequently compute these checks but fail to define release thresholds in advance. That weakens governance: every launch becomes an argument about whether the current results are "good enough." Decide the thresholds before training when possible.
def release_gate(report: dict) -> tuple[bool, list[str]]:
failures = []
if not report["schema_ok"]:
failures.append("schema validation failed")
if report["detection_auc"] > 0.78:
failures.append("synthetic data is too easy to distinguish from real data")
if report["tstr_auc"] < 0.84:
failures.append("downstream utility below threshold")
if report["nearest_neighbor_risk"] > 0.18:
failures.append("privacy risk above threshold")
if report["worst_group_gap"] > 0.05:
failures.append("subgroup fidelity gap too large")
return len(failures) == 0, failures14.4 Privacy Budgets, Lineage, and Approvals
The operational story changes substantially if differential privacy is involved. In that setting, every release can consume part of a shared privacy budget. The budget must be tracked centrally, not in a notebook comment or a Slack thread. A release should record the privacy mechanism, accounting method, target epsilon or delta when relevant, and who approved the consumption.
Even without formal differential privacy, lineage matters. At minimum, store:
- source data snapshot identifier
- generator code version or commit hash
- model parameters and random seed
- validation report identifier
- release timestamp and approver
These fields make incident response possible. If a downstream team reports suspicious drift or privacy concerns, you need to know exactly which upstream ingredients produced the dataset.
14.5 Monitoring After Release
Synthetic datasets degrade operationally even when they look statistically stable at release time. Real-world processes drift. Fraud tactics change. Sensor firmware changes. Product flows change. A synthetic dataset that was acceptable in January may become actively misleading in June.
Post-release monitoring should answer three questions:
- Is the real source distribution drifting? If yes, the generator may need retraining.
- Is utility degrading? Re-run downstream benchmark tasks against fresh holdout data.
- Are high-risk subgroups diverging first? Monitor slices, not just aggregate averages.
14.6 Rollback and Incident Response
Every production synthetic data pipeline needs a rollback path. If an auditor flags leakage, if a downstream model regresses, or if a transformation bug corrupts timestamps, you should be able to revoke the current release and re-issue the last known-good version without improvisation.
A minimal incident playbook includes:
- freeze distribution of the affected dataset version
- identify all downstream consumers
- compare the current manifest against the last successful release
- restore the prior approved dataset if safe
- open a corrective-action review before the next release
Mature teams also classify incidents. A schema drift incident, a privacy incident, and a utility regression do not have the same blast radius, so they should not be handled with the same urgency or ownership chain.
14.7 Hands-On: Build a Simple Release Report
The following pattern turns validation outputs into a release-ready report. It is intentionally lightweight and works well as a first operational layer before you build a larger internal platform.
from datetime import datetime, timezone
def build_release_report(dataset_name: str,
generator_name: str,
source_snapshot: str,
metrics: dict) -> dict:
approved, failures = release_gate(metrics)
return {
"dataset_name": dataset_name,
"generator_name": generator_name,
"source_snapshot": source_snapshot,
# datetime.utcnow() is deprecated in Python 3.12+; use a
# timezone-aware UTC timestamp instead.
"released_at": datetime.now(timezone.utc).isoformat(),
"metrics": metrics,
"approved": approved,
"failures": failures,
}
metrics = {
"schema_ok": True,
"detection_auc": 0.74,
"tstr_auc": 0.87,
"nearest_neighbor_risk": 0.11,
"worst_group_gap": 0.03,
}
release_report = build_release_report(
dataset_name="fraud_synthetic_v2026_04",
generator_name="CTGANSynthesizer",
source_snapshot="warehouse://fraud/train/2026-04-01",
metrics=metrics,
)
print(release_report["approved"])
print(release_report["failures"])This report can be stored next to the dataset, attached to a pull request, or emitted into an internal catalog. The important part is that release status becomes machine-readable rather than anecdotal.
14.8 Operational Checklist
- Define intended use before training.
- Version the source snapshot, generator code, and parameters together.
- Require schema, quality, privacy, and subgroup gates before release.
- Track privacy budget or empirical risk reports per release.
- Monitor downstream utility after release, not just training metrics.
- Keep rollback-ready prior releases and their manifests.
Synthetic data fails in production for the same reason many ML systems fail in production: the surrounding engineering discipline lags behind the modeling ambition. Synthetic Data Ops is the layer that closes that gap.
References
- (2015). Hidden Technical Debt in Machine Learning Systems. Advances in Neural Information Processing Systems. papers.nips.cc
- (2019). The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction. IEEE Big Data. research.google
- (2019). Data Validation for Machine Learning. CIDR. proceedings.cidrdb.org
- (2020). Practical Synthetic Data Generation: Balancing Privacy and the Broad Availability of Data. O'Reilly Media.
- (2014). The Algorithmic Foundations of Differential Privacy. Foundations and Trends in Theoretical Computer Science. cis.upenn.edu